Семплирование — это процесс, при котором анализируют небольшую часть данных, чтобы получить представление о характеристиках и параметрах всей собранной информации.
Термин образован от английского «sample», что переводится как проба или образец.
В Рунете встречается два варианта написания слова: семплирование и сэмплирование. С точки зрения грамматики первый вариант верный. Однако слово «сэмплирование» также часто используется.
В математике под семплированием понимают набор методов, с помощью которых формируют выборку — то есть отбирают небольшой кусок данных из большого объема информации.

Чтобы понять, из чего состоит и какая на вкус пицца, не нужно есть её всю. Достаточно попробовать один кусочек. По этому принципу и работает семплирование. Выводы о характеристиках и качествах большой группы данных делают, изучив только ее часть
В интернет-маркетинге о семплировании говорят в контексте отчетов веб-аналитики.
Представим, что на сайт зашло 100 пользователей, из них 11 человек перешли по ссылке из соцсетей. Пользователей мало, программа легко отследит каждую операцию, посчитает и сформирует отчет.
Ситуация выглядит иначе, когда на сайт заходит 10 000 000 пользователей. Проанализировать действия каждого сложно, для этого потребуются большие вычислительные мощности.
Чтобы облегчить задачу, программа делает выборку в 10%. С помощью специальных математических методов отбирают 1 000 000 человек, из них 117 000 перешли на сайт из социальных сетей.
Далее программа умножает эту сумму на 10 и в итоговом отчете показывает, что из 10 000 000 посетителей сайта 1 170 000 человек пришло из соцсетей.
Когда применяется семплирование данных
Семплирование данных используется в различных аналитических инструментах. Google Analytics и «Яндекс.Метрика» прибегают к семплированию при обработке больших объемов информации и подготовке отчетов веб-аналитики. Это происходит, когда количество сессий превышает определенный лимит.
Рассказываем, как работает семплирование.
Семплирование в Google Analytics
В стандартных отчетах Google Analytics семплирование не используется. Это вкладки «Аудитория», «Источники трафика», «Поведение» и «Конверсии». Сервис хранит полный набор данных в таблицах.
Семплирование в Google Analytics возникает в следующих случаях.
При обработке специальных запросов, когда необходимо обработать слишком большой объем данных. Лимит составляет 500 000 сеансов в стандартной версии или 100 000 000 сеансов при подключении Google Analytics 360.
К специальным запросам относят:
- создание пользовательского отчета с уникальным перечнем показателей и характеристик;
- добавление в отчет по умолчанию дополнительных параметров;
- применение фильтров и сегментов.
При модификации отчета по многоканальным последовательностям. Многоканальная последовательность – это путь, который показывает все точки касания пользователя с компанией от первого знакомства до покупки.
Большинство клиентов не сразу совершают покупку. Например, сначала он случайно перешел по рекламной ссылке, запомнил магазин, спустя неделю ввел его название в поисковик, положил товары в корзину, а уже на следующий день оплатил заказ. Все эти действия отслеживают системы аналитики. Это большой объем информации.
При добавлении параметров и фильтров Google Analytics использует семплирование. Максимальный размер выборки в этом случае 1 000 000 сеансов.
Чтобы понять, какие данные сервис использует для построения отчета, нужно посмотреть на цвет иконки в виде щита. Если иконка зеленая, для отчета использована полная информация о действиях пользователей. Если оранжевая — представлены результаты для выборки.
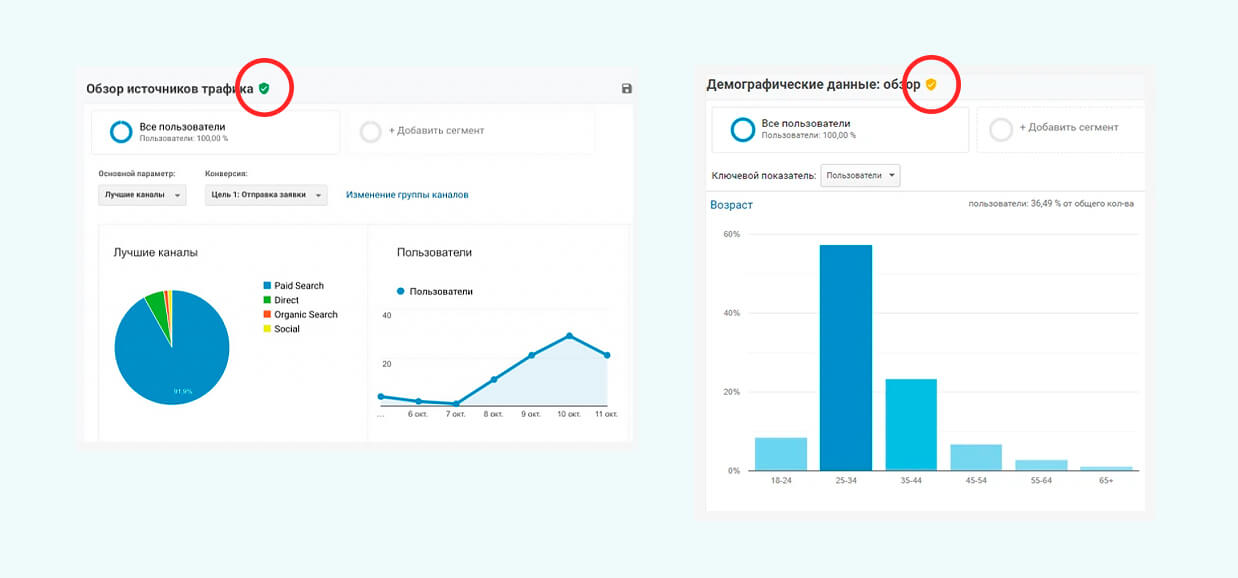
При анализе данных обратите внимание на иконку в виде щита
Google Analytics предлагает выбрать два варианта работы с выборкой:
- более точные результаты — для построения отчета используют максимально возможную выборку;
- быстрая обработка — анализируют небольшой образец данных, чтобы быстро получить отчет.
Семплирование в «Яндекс.Метрике»
«Яндекс.Метрика» использует семплирование при составлении аналитических отчетов. Лимит составляет 500 000 сеансов в стандартной версии, при подключении услуги «Метрика Про» ограничения отсутствуют. Семплирование не используют при формировании отчетов категории «Директ». Система также хранит все исходные данные.
Чтоб понять, применит ли «Яндекс.Метрика» семплирование для конкретного отчета, нужно посмотреть значение показателя «Точность». Если он равен 100% — данные полные. Если ниже — программа обращается к выборке.
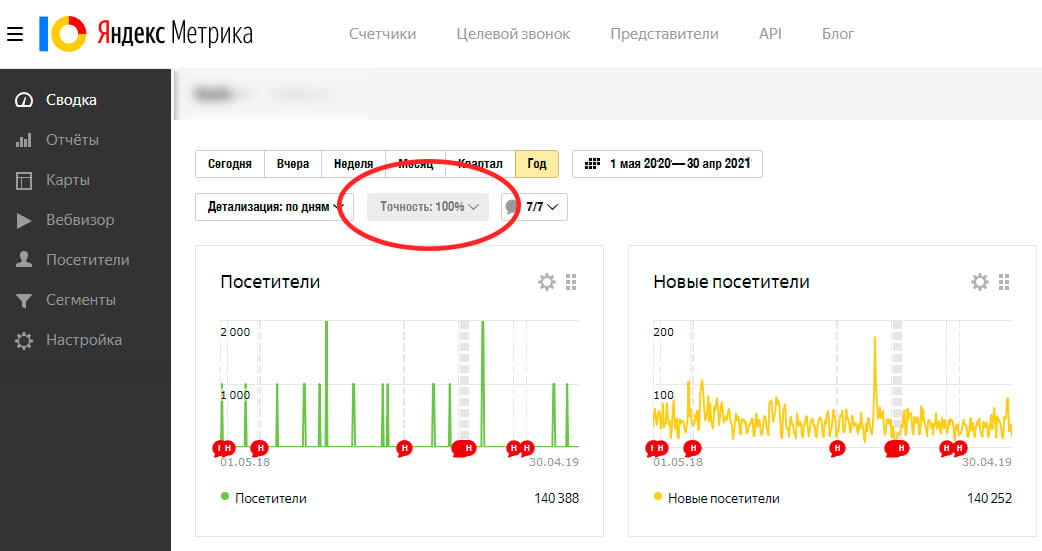
Почему семплирование данных — это плохо
При семплировании анализируются не все данные, поэтому часть информации может потеряться. При работе с выборкой в результате анализа можно упустить некоторые детали или тенденции, которые оказались в другой части данных.
Рассмотрим наглядный пример. У нас есть коробка шариков. Чтобы узнать все цвета и размеры, достаточно осмотреть каждый. Когда шариками заполнена целая комната, то потребуется слишком много времени, чтобы изучить их все. Поэтому мы используем семплирование: берем часть шариков и смотрим на них.
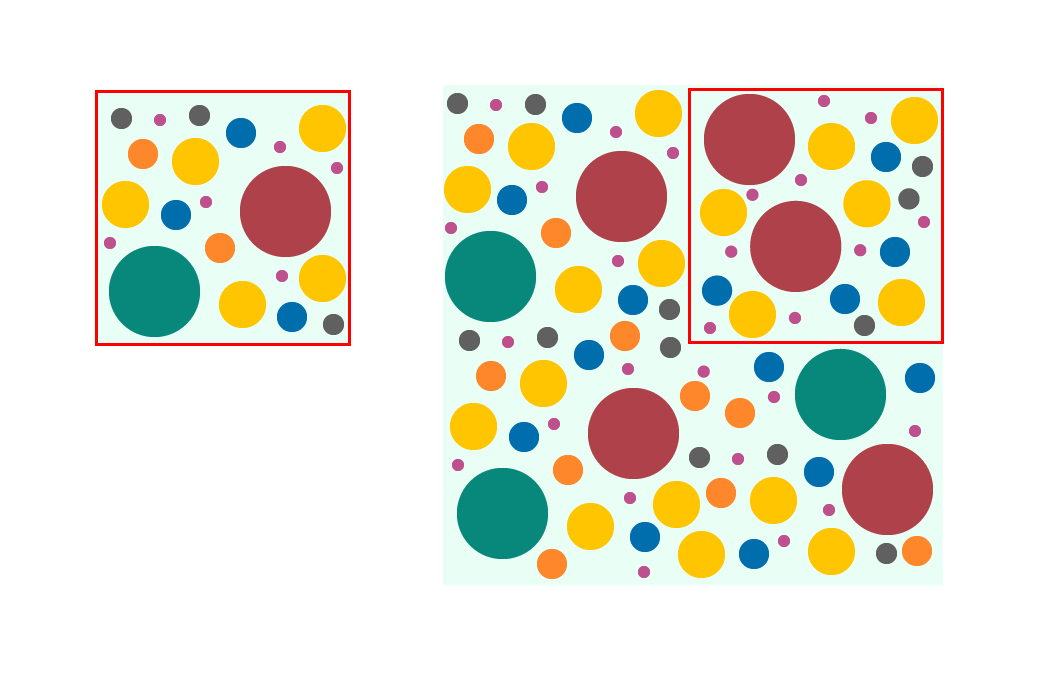
Как видно на картинке, не все шарики из большого квадрата попали в выборку. Там нет ни одного зеленого и оранжевого. Если мы будем смотреть только на выборку, то никогда не узнаем о существовании больших зеленых и маленьких оранжевых шаров.
Семплирование при работе с большими объемами информации сокращает время, потраченное на анализ, и снижает нагрузку на сервера. Полностью от него отказаться не всегда возможно. Поэтому нужно найти оптимальное соотношение между объемом выборки и допустимой погрешностью. Алгоритмы семплирования совершенствуются, чтобы собирать наиболее показательную выборку, которая максимально соответствует по характеристикам полному объему данных.
Как избежать семплирования данных в аналитических отчетах
Избежать семплирования и повысить точность отчетов в «Яндекс.Метрике» и Google Analytics помогут следующие действия:
- Уменьшить период анализа. Составить отчет за более короткий временной период.
- Увеличить объем и точность выборки. Это можно сделать вручную, щелкнув на иконку в Google Analytics или выбрав нужное значение «Точности» в «Яндекс.Метрике».
- Использовать дополнительные инструменты. Подключить «Метрика Про» или Google Analytics 360, BI-системы и другие альтернативные сервисы.
- Создать отдельный кабинет для каждого сайта. Отслеживать все ресурсы в одном кабинете удобно, но если данных много, разделите их.
Главные мысли







