

Robots.txt — это текстовый документ с рекомендациями для роботов поисковых систем. Указания в нём разрешают либо запрещают сканирование сайта и отдельных его страниц. Файл размещают в корневом каталоге сайта.
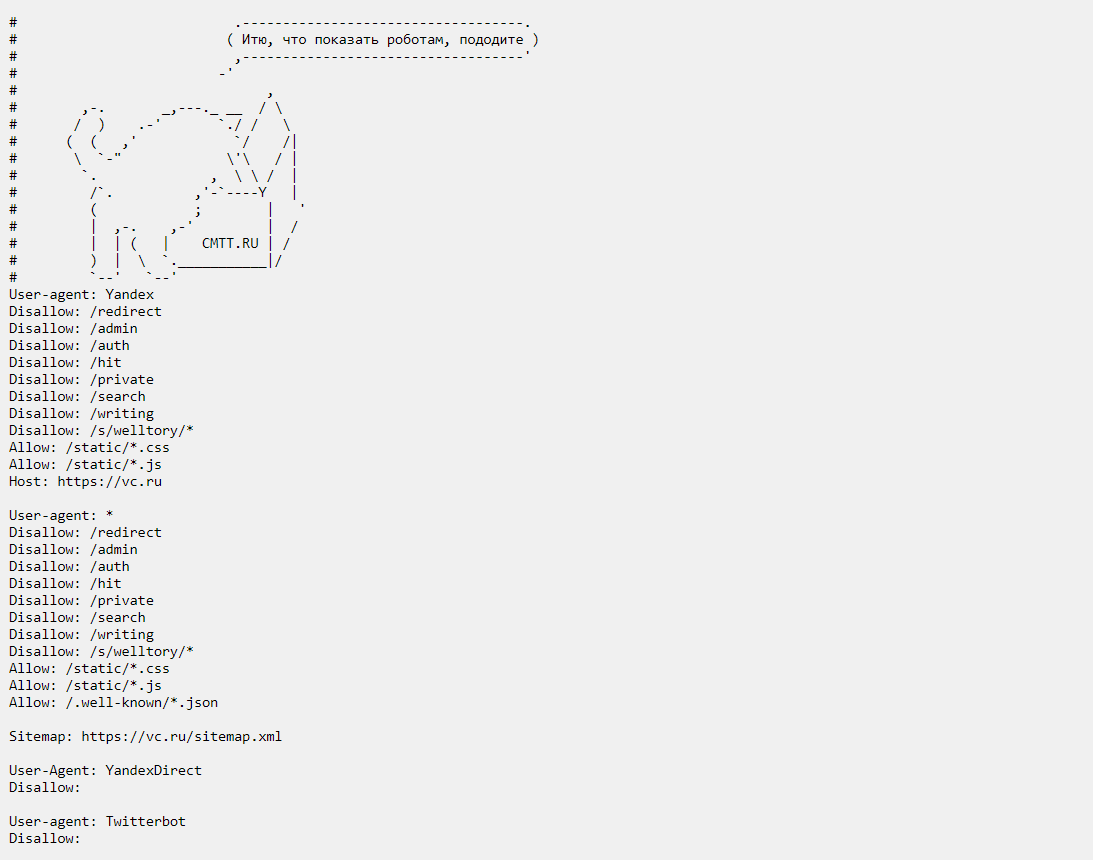
Это документ robots.txt сайта VC. В нем видно, что отдельные разделы сайта не нужно индексировать. Источник
Для чего нужен robots.txt
Главная задача правильного robots.txt — указать поисковым роботам на страницы, которые нужно просканировать или проигнорировать. В противном случае роботы-краулеры проиндексируют сайт по своему усмотрению с учётом SEO-параметров и оптимизации. В результате индексации в публичном доступе могут оказаться служебные страницы, конфиденциальные файлы и дубли. А это отрицательно повлияет на продвижение ресурса.
Также файл ограничивает число запросов на сканирование, что снижает нагрузку на сайт и положительно влияет на оптимизацию.
Файл robots.txt не относят к обязательным и используют на усмотрение SEO-специалистов. Работу над ним часто проводят в рамках внутренней оптимизации и внешнего SEO при продвижении сайта.
Файл robots.txt SEO-специалисты считают обязательным и важным. В нём можно корректировать все, что нужно видеть пользователю, а что нельзя, добавляется ссылка на карту сайта и т.д. Дополнительно можно писать правила использования для ботов разных поисковиков.

Как создать robots.txt
Для создания robots.txt подойдёт любой текстовый редактор — «Блокнот» в Windows или TextEdit в macOS.
Важно соблюдать критерии оформления документа:
- название файла — robots (ROBOTS);
- формат файла —txt;
- тип кодировки — UTF-8.
Созданный пустой документ robots.txt уже можно добавить на сайт. Роботы признают его разрешающим. Чтобы управлять индексацией, необходимо указать в файле правила относительно определённых страниц.
Обычно в robots.txt закрывают страницы, которые не предназначены для всеобщего доступа и SEO: страницу авторизации и личный кабинет, технические директории и админ-панели, конфиденциальные файлы и страницы.
Директивы robots.txt
Это команды для поисковых роботов. В robots.txt их прописывают одной либо несколькими группами — каждую директиву с новой строки. Директивы дополняют правилами — для какого агента пользователя (робота поисковых систем) предназначены инструкции, какие файлы обрабатывать и какие страницы игнорировать. Правила прописывают с учётом регистра.
В файле разрешено использовать лишь латиницу, потому весь текст на русском необходимо перевести с помощью Punycode-конвертера;
Строки в группе записывают в следующем формате:
<field> : <value>
- field — название директивы;
- value — указание правила (параметра, страницы, раздела или файла).
Директивы структурируются, объединяются и образуют корневые папки. Их называют директориями. В них хранятся все каталоги и файлы сайта. Именно от них начинается отсчет пути к файлу или папке. Загрузить что-либо выше нее — невозможно.
Если параметр директивы является директорией, то перед её названием в robots всегда ставят слеш «/»: Disallow: /category
User-agent. Каждая группа правил начинается строкой с директивой User-agent. Она сообщает, какому роботу адресованы указания. Запись для поискового робота Google:
User-agent: Googlebot
Создать User-agent для робота «Яндекса» следует так:
User-agent: Yandex
Когда нужно указать, что правила одинаковы для всех роботов, то указывают символ «звёздочка»:
User-agent: *
После User-agent следуют конкретные указания для агента, выраженные подходящими директивами.
Disallow. Это обязательная директива. Она следует сразу после User-agent и запрещает сканирование внутри сайта. В директиве прописывают страницу и каталог корневого домена, которые не подлежат индексации.
Чтобы закрыть от индексации весь сайт, нужно создать такую запись:
User-agent: *
Disallow: /
Для ограничения доступа к определённому каталогу в Disallow указывают его название:
User-agent: *
Disallow: /blog/
Для закрытия конкретной страницы указывают её URL без хоста:
User-agent: *
Disallow: /blog/page1
Allow. Необязательная директива Allow разрешает индексацию. При её отсутствии роботы Google и «Яндекс» по умолчанию просканируют весь сайт. Но с помощью данной директивы можно открыть роботам доступ к файлам, которые расположены в закрытой части.
Иногда для SEO важно продвинуть в поиске какую-то оптимизированную страницу из закрытой директории. Например, необходимо повысить посещаемость страницы каталога с полным перечнем товаров. При этом страницы конкретных продуктов продвигать не планируется. Чтобы разрешить сканирование одной страницы в закрытом разделе можно создать такую запись:
User-agent: *
Disallow: /katalog/
Allow: /katalog/page1/
Clean-param (только для «Яндекса»). Указывает роботу «Яндекса» на параметры страницы, которые не следует учитывать при сканировании. Google не поддерживает Clean-param.
Синтаксис директивы таков:
Clean-param: p0[&p1&p2&...&pn] [path]
- внутри первой пары скобок — через символ & перечисляют параметры, которые не следует сканировать;
- во втором поле пишут префикс пути страниц, для которых предназначено правило.
Некоторые страницы дублируются с разными UTM-метками. Директива помогает исключить их индексацию. Краулеры не будут сканировать все варианты таких страниц.
Clean-param: utm_source&utm_medium&utm_term&utm_content
В «Яндексе» Clean-param дополняет Disallow или становится его альтернативой. Директива позволяет запретить индексацию страниц внутри раздела.
User-agent: Yandex
Clean-param: s&ref /forum*/showthread.php
Sitemap. Межсекционная директива Sitemap отображает путь к XML-карте сайта. XML-карта помогает роботам индексировать ресурс, поскольку показывает структуру сайта и упрощает навигацию. Директиву Sitemap размещают в любом месте файла robots.txt без привязки к конкретной группе User-agent. При создании правила ссылку на файл Sitemap указывают полностью:
Sitemap: https://example.com/sitemap.xml
Внимание! По завершении работы над robots.txt проверьте вес получившегося файла. Максимальный размер файла ограничен: не более 500 KB. Слишком большой файл не читается. А значит, все страницы будут проиндексированы краулерами.
Спецсимволы в robots.txt
Дополнительно в robots.txt часто используют специальные символы, которые уточняют понимание правил.
Звёздочка. Символ * используют, чтобы запретить индексирование страницы по этому адресу. Если указанное правило присутствует в любой части URL, то краулеры не будут учитывать даже подразделы.
Disallow: /catalog*
Данная директива запрещает доступ к разделу /catalog, а также ко всем подразделам, например /catalog1.
По умолчанию каждое правило Allow и Disallow с частичным URL заканчивается «звёздочкой». Поэтому добавлять его в конце каждой строки необязательно:
Disallow: /catalog* = Disallow: /catalog
Решётка. Символ # решётки используют для добавления различных комментариев в файл robots.txt. Всё, что написано в строке после # и до первого переноса, поисковые роботы просто проигнорируют. Это позволяет оставлять заметки для коллег или «послания» для случайных посетителей.
User-agent: *
Disallow: /catalog/
Allow: /catalog/page1/
#файл создан в 7531 году от сотворения мира
Так разработчики оставляют «пасхалки» — юмористические сообщения для тех, кто решил покопаться в общедоступном коде ресурса. Так файл robots.txt на YouTube гласит: «Создан в далеком будущем (2000 год) после восстания роботов середины 90-х, уничтожившего всех людей».
Доллар. Символ $ ставят в конце URL-адреса, чтобы отменить спецсимвол «звёздочка».
Данная директива запрещает доступ к разделу /catalog, но раздел /catalog1 — будет доступен:
Disallow: /catalog*$
Важно! Иногда для создания robots.txt используют специальные сервисы (SEOptimer, «Генератор файла robots.txt»). Но даже в этом случае, желательно проверить файл вручную и понимать, как работают директивы. Это позволит внести важные поправки.
Как загрузить и проверить robots.txt
Готовый файл robots.txt, сохранённый на устройстве, загружают в корневой каталог сайта. Способ загрузки зависит от архитектуры сайта и сервера. Так в конструкторе сайтов файл загружают и включают в настройках.
После загрузки нужно проверить доступность файла. Для этого откройте окно в режиме инкогнито и введите адрес в следующем формате:
https://ваш_сайт.com/robots.txt
Далее следует проверить работоспособность файла, верно ли его считывают роботы. Для этого используйте инструменты поисковых систем:
- Google — через Google Search Console (только для владельца сайта);
- «Яндекс» — в «Вебмастере» (для любых сайтов).
Существует способ, который позволяет просмотреть robots.txt практически любого сайта. Для этого укажите в поисковой строке адрес ресурса и стандартный путь к файлу — «site.ru/robots.txt/».
Типичные ошибки в настройке файла robots.txt
Среди частых ошибок в robots.txt выделяют следующие:
| Ошибка | Значение | Следствие |
| Пустая директива User-agent (или отсутствие директивы) | Не указано, для каких поисковых роботов предназначены правила | Полная невалидность robots.txt |
| В начале правила Disallow или Allow отсутствует символ «/» или «*» | Отсутствие чёткого указания на раздел или директорию | Неработоспособность директивы Disallow или Allow |
| Указание «Disallow: /» для действующего сайта | Закрытие всего содержимого ресурса | Сайт будет исключён из индекса |
| Отсутствие знака «:» между директивой и правилом | Невозможность прочтения роботами | Указание не будет учтено |
Как поисковые системы понимают файл robots.txt
Восприятие файла robots.txt поисковыми системами Google и «Яндекс» несколько отличается:
- «Яндекс» строго соблюдает правила. Если страница закрыта директивой Disallow, то она не будет сканироваться. Если файл robots не отвечает требованиям, сайт открыт для индексации.
- Google не всегда следует правилам в точности. Наличие директивы Disallow воспринимается как рекомендация, но не запрет. Потому целесообразнее защищать непубличные страницы паролем или директивой noindex.
Содержимое файла robots.txt — это лишь рекомендации для роботов, а не строгие инструкции. Боты проигнорируют запрет и просканируют закрытые в robots.txt страницы, если на них ссылаются внешние ресурсы. Чтобы полностью заблокировать индексацию ресурса, используйте рекомендации от «Яндекс» и Google.
Обязательно учитывайте, что у разных CMS (админок сайта) есть свои рабочие папки, которые нужно правильно закрывать и открывать для ботов поисковиков, чтобы не индексировался мусор либо не была закрыта важная информация.
Главные мысли







