

Поисковый робот (web crawler, или веб-паук) — это специальная программа, которая в автоматическом режиме сканирует веб-страницы и передает собранные данные поисковой системе или компании-владельцу.
Самые известные пользователи краулеров — поисковики. Их пауки переходят по доступным ссылкам, собирают и анализируют содержимое страниц в интернете и отправляют полученные данные на сервер поисковой машины, чтобы пополнить и обновить выдачу.
Помимо HTML-страниц, такие краулеры сканируют документы и других форматов. Например, Adobe PDF (.pdf), Microsoft Excel (.xls, .xlsx), Microsoft PowerPoint (.ppt, .pptx) и Microsoft Word (.doc, .docx).
Зачем нужен поисковый робот
Поисковые роботы — ключевой элемент работы поисковой системы и связующее звено между опубликованным контентом и пользователем. Если веб-страница не просканирована и не добавлена в базу поисковика, она не появится в выдаче. Попасть на нее можно будет только по прямой ссылке.
Роботы также влияют на ранжирование. Например, неизвестные краулеру API и функции JavaScript мешают корректно просканировать сайт. В результате на сервер отправляются страницы с ошибками, а часть контента на них и вовсе может оказаться в слепой зоне робота.
Поскольку на следующих этапах поисковые системы применяют к полученным данным специальные алгоритмы для выдачи пользователям более релевантной информации, такие некачественные страницы могут оказаться на дне поиска.
Как работает поисковый робот
Прежде чем сайт или файл попадет в базу поисковой системы для дальнейшего ранжирования, робот должен его найти. Чаще всего это происходит автоматически: страницы обнаруживаются при переходе по ссылкам с уже известных боту разделов сайта. Например, при переобходе блога паук фиксирует появление новой записи в нем и вносит ее в расписание следующего обхода.
Если на сайте есть файл sitemap.xml (карта сайта), то при каждом его обновлении краулер считывает оттуда ссылки для сканирования.
Передать роботу конкретный URL на сканирование можно и вручную. Для этого нужно подключить сайт к «Яндекс.Вебмастеру» (или Google Search Console) и ввести в специальном разделе ссылку на страницу, которая должна быть проиндексирована.
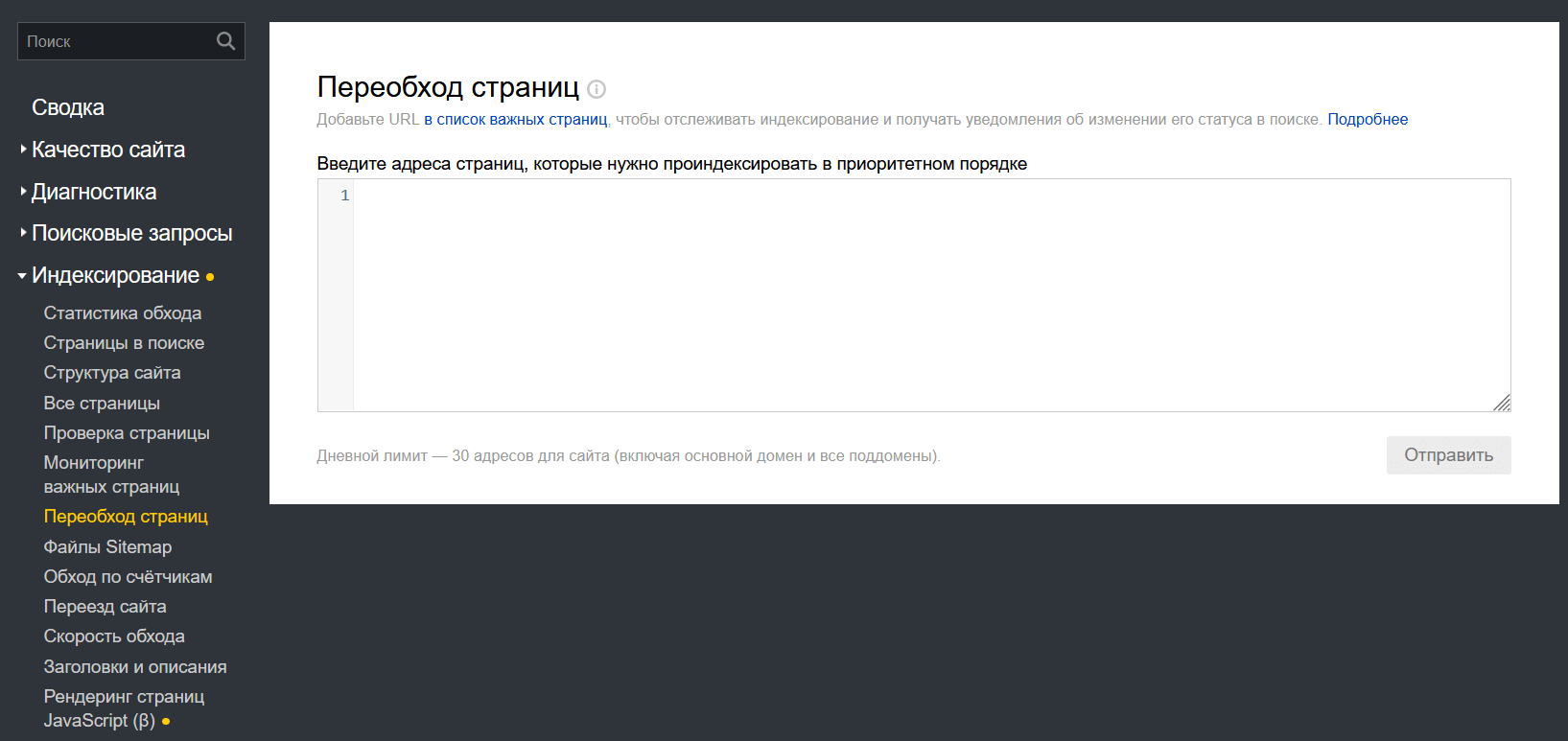
Интерфейс инструмента «Яндекс.Вебмастера» для ручного добавления страниц в очередь на индексацию
Далее, если страница доступна, происходит ее сканирование. Краулер считывает текстовое содержимое, теги и гиперссылки.
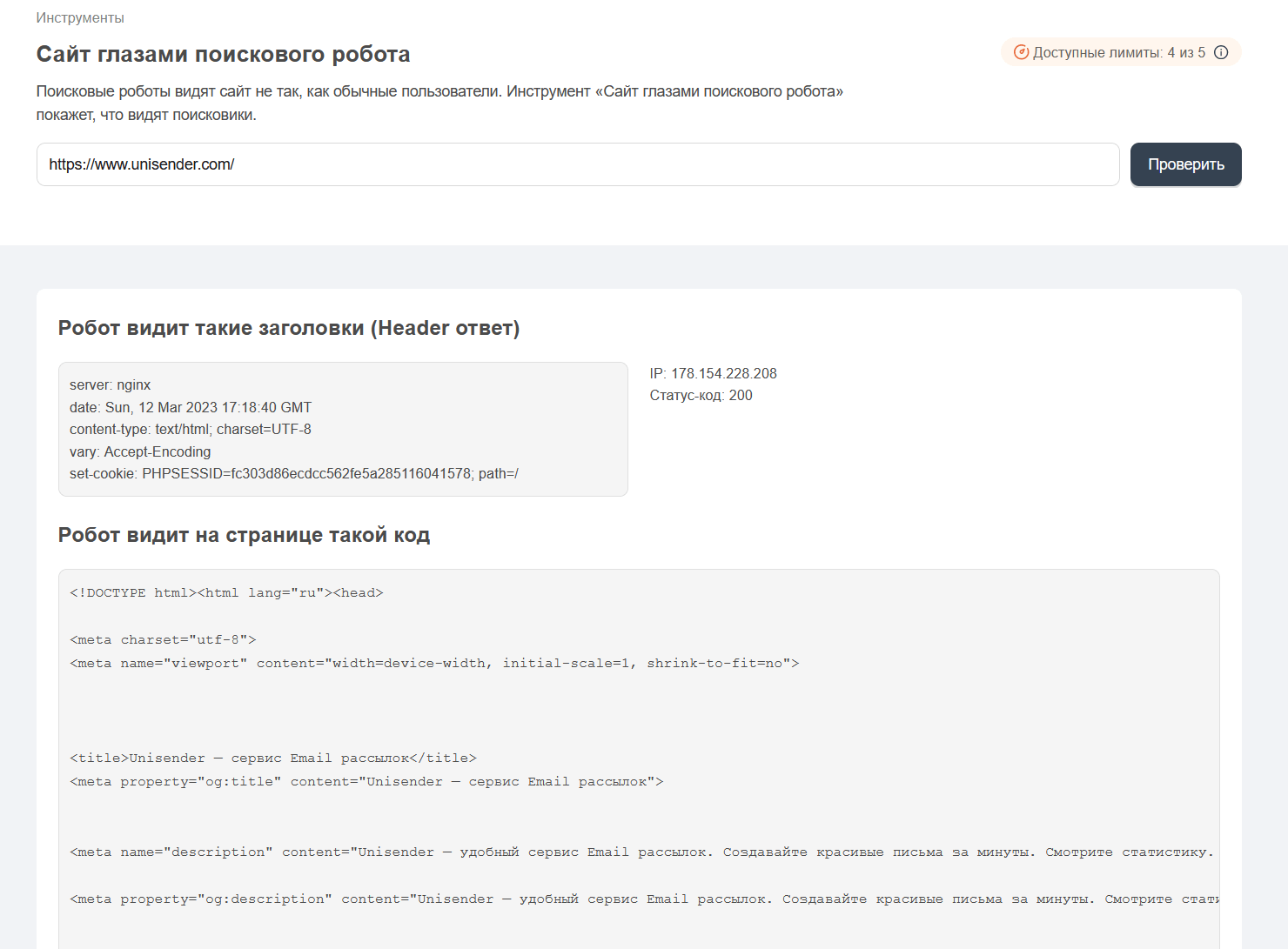
Так робот видит главную страницу сайта Unisender. Источник
Затем веб-паук загружает полученные данные на сервер для дальнейшей их обработки.
Далее содержимое страницы очищается от лишних HTML-тегов, структурируется и помещается в базу поисковой машины (индекс). Фактически индексацией занимается другой робот. Однако зачастую индексного бота считают частью или разновидностью поискового.
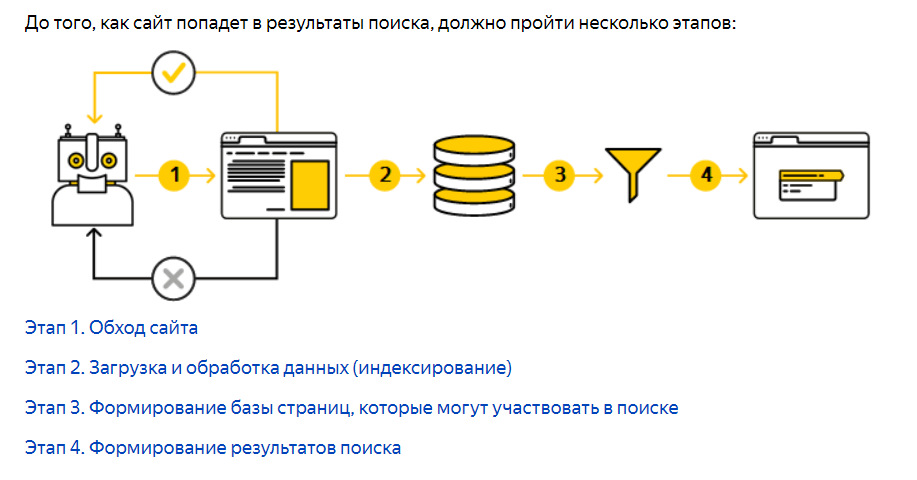
Описание работы поиска «Яндекса». Первые 2 этапа выполняет поисковый робот. Источник
Скорость индексации у разных поисковых систем различается. «Яндекс» добавляет новые страницы в выдачу в течение нескольких дней, в то время как боты Google справляются с задачей за несколько часов.
Если сайт только запускается в работу, и поисковая система еще не знает ни одного его раздела, полное сканирование и индексация может занять несколько месяцев.
Роботы не ограничиваются разовым посещением интернет-ресурса. Они также отслеживают изменения и сообщают поисковой машине об удалении или перемещении уже проиндексированных страниц. Периодичность обхода при этом зависит от объема трафика, размера и глубины сайта, а также частоты обновления контента на нем.
Какие бывают роботы
Самые известные веб-пауки принадлежат поисковым системам. Их функция — добавлять и актуализировать данные в поисковой выдаче. Помимо основных роботов у каждого сервиса есть специализированные, которые скачивают изображения, видео, новости и т.д.
У Googlebot, главного поискового робота Google, есть несколько помощников: Googlebot-Image выполняет поиск изображений, Googlebot-Video отвечает за видео-контент, а Googlebot-News пополняет списки новостного портала.
«Яндекс» также отправляет отдельных пауков сканировать интернет для своих сервисов от «Маркета» до «Аналитики». А над обновлением поиска трудятся два главных робота — основной и быстрый под названием Orange.
Если стандартное индексирование страниц занимает от нескольких дней, то ускоренное позволяет добавить в поиск файлы, созданные минутой назад. В такую быстровыдачу попадают онлайн трансляции, новостные и букмекерские сайты и другие ресурсы, помогающие пользователю получать важную информацию в режиме реального времени.
Отобранные Orange страницы висят в специальной выдаче три дня, после чего заново индексируются основным роботом для размещения в общем каталоге поиска.
Важно понимать, что в ускоренный индекс попадает ограниченное количество ресурсов, отвечающих конкретным требованиям. Простой информационный или продающий ресурс с новостным отделом не попадет в ускоренную новостную индексацию.

Свои краулеры также есть у Mail.ru и менее популярных поисковых сервисов: Bing, Yahoo, DuckDuckGo, Baidu и др.
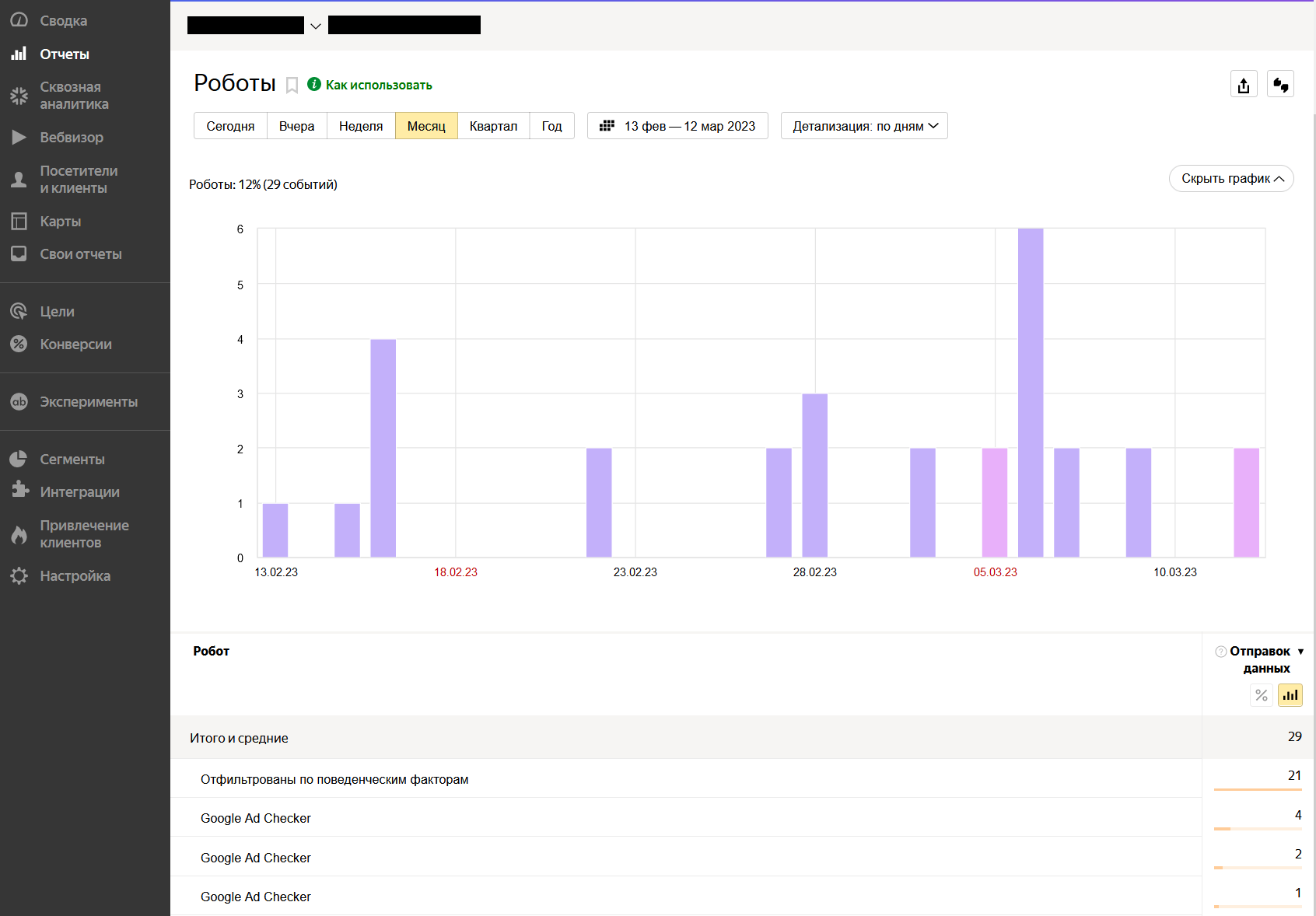
Статистика посещений сайта роботами в отчете «Яндекс.Метрики»
Роботов поисковых систем неофициально называются «вежливыми». Они не притворяются живыми пользователями и их посещения легко отслеживаются в инструментах аналитики. Каждый паук имеет уникальное имя — User-Agent.
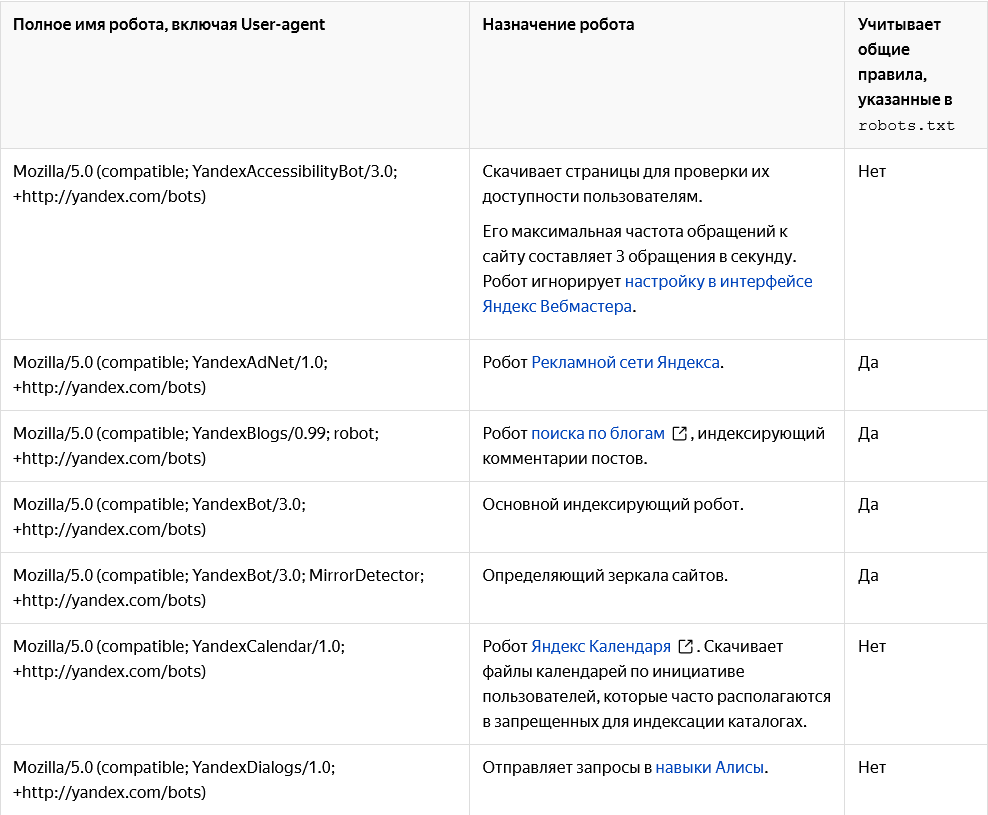
Имена некоторых роботов «Яндекса». Источник
Однако сканированием и индексированием страниц занимаются не только поисковые системы. Свои роботы (парсеры) есть у сервисов аналитики и SEO. Например, Amazonbot сканирует интернет для улучшения внутренних сервисов и обучения поискового ассистента Алексы.
В свою очередь, такие SEO инструменты, как Ahrefs Bot, Semrush Bot и Screaming Frog, собирают открытые данные для своих клиентов. С их помощью владелец страницы или маркетолог может проверить сайты конкурентов, выявить технические проблемы собственных ресурсов и выстроить стратегию продвижения.
Существует немало и так называемых «вредных» роботов. Они мимикрируют под пользовательские браузеры или копируют имена известных поисковых краулеров, чтобы парсить информацию с сайтов для дальнейшего коммерческого использования. На основе собранных ими данных создаются базы для холодных звонков и email-рассылок.
Проблемы, которые могут возникнуть при работе поисковых роботов
Неполная и медленная индексация сайтов
Чем больше страниц и поддоменов у сайта, тем сложнее роботу обойти его полностью. Если структура сайта не очевидна, а перелинковка отсутствует, полная индексация может растянуться на месяцы.
Ошибки в верстке и наличие дублей также замедляют попадание страниц в поисковую выдачу, что негативно сказывается на продвижении сайта.
Повышенная нагрузка на сервер
Частые набеги краулеров, имитирующих посещения живых пользователей, увеличивают нагрузку на серверы. Это может привести к перебоям в работе веб-ресурса и сделать его временно недоступным.
Роботы известных поисковых систем совершают обход по расписанию и придерживаются лимитов, поэтому обычно не перегружают серверы. Однако при публикации сразу нескольких сотен страниц, например, карточек интернет-магазина, пиковая нагрузка все же может вырасти в разы.
В этом случае специалисты поисковых машин советуют вручную ограничивать частоту обхода страниц роботами или настроить сервер так, чтобы он возвращал HTTP-код 429. Такой ответ считывается краулерами как сигнал о проблемах с нагрузкой, и они автоматически уменьшают число обращений к серверу.
Утечка незащищенной информации
По умолчанию робот обходит все известные ему страницы, если доступ к ним не закрыт владельцем сайта. Ошибки в настройках конфиденциальности и отсутствие запретов на индексацию приводят к утечкам материалов, не предназначенных для публикации в сети.
Так, в 2018 году в поисковой выдаче «Яндекс» появились данные клиентов банков и транспортных компаний. Незадолго до этого в открытом доступе также оказались личные документы пользователей Google Docs.
Как повлиять на работу роботов
Скорость обхода и оценка качества страниц зависит от их технического состояния. Устранение проблем хостинга, настройка редиректов, удаление неработающих ссылок и дублей страниц повышает шансы на быструю индексацию и размещение веб-ресурса на первой странице поисковой выдачи. Эти операции входят в комплекс мероприятий по оптимизации и продвижению сайта в поисковых системах (SEO).
Самый простой способ ускорить индексацию страниц — внедрить на сайт системы веб-аналитики, принадлежащие поисковым сервисам. Например, Google Analytics, «Яндекс.Метрику» и Рейтинг@Mail.ru.
Следующий шаг — подключение сайта к инструментам Google Search Console и «Яндекс.Вебмастер». Они позволяют отследить статус обхода страниц и исправить технические ошибки, мешающие индексации.
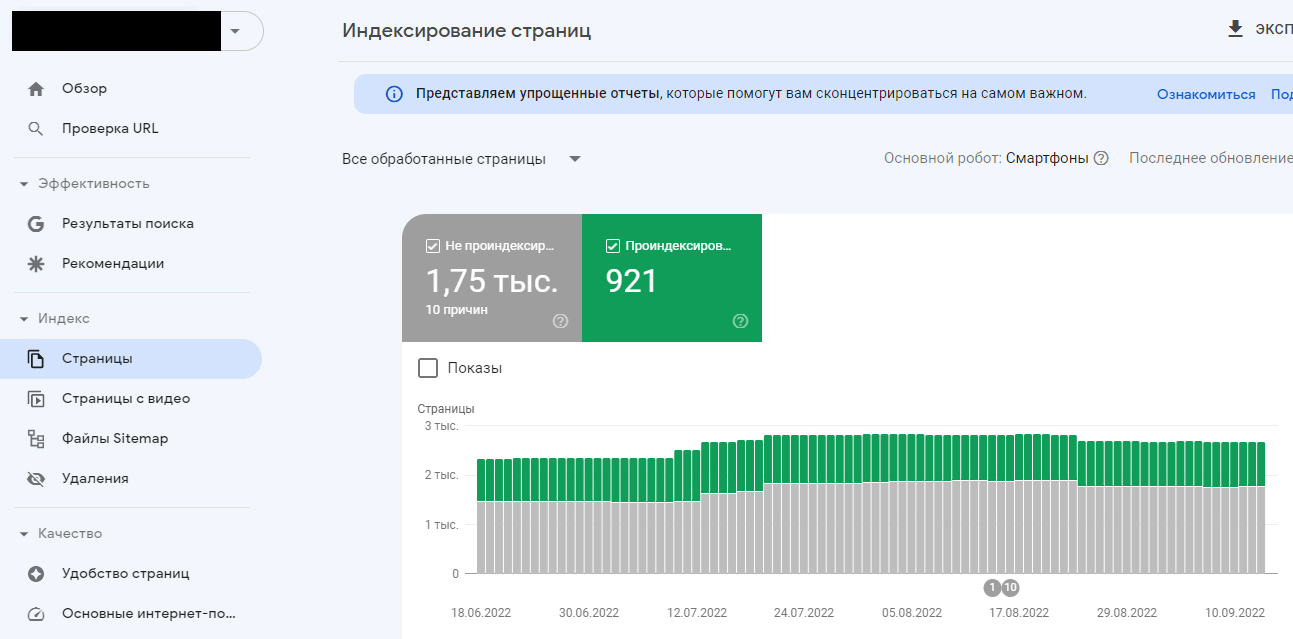
Статистика индексирования страниц в Google Search Console
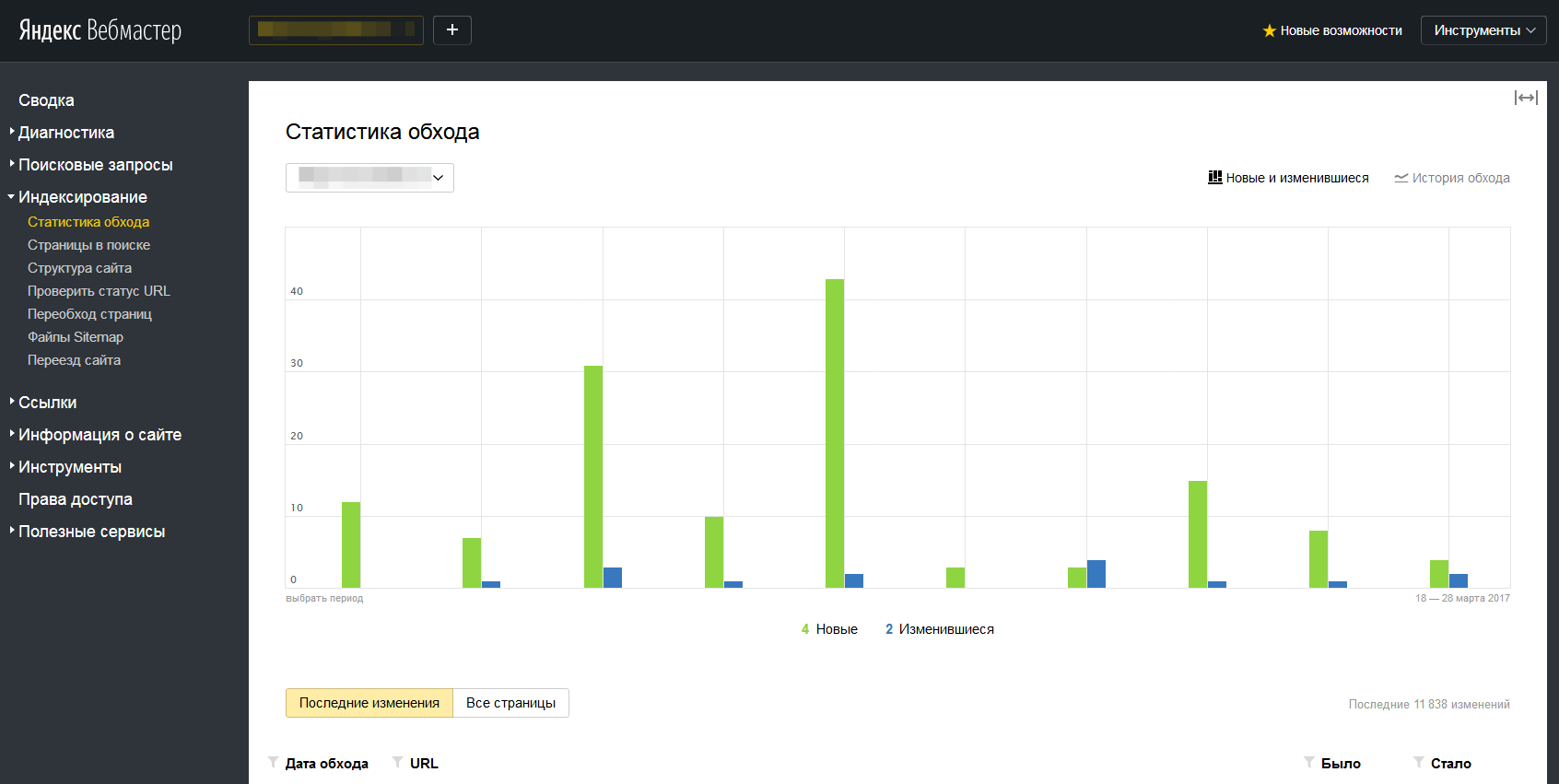
Аналогичный инструмент в «Яндекс.Вебмастере» показывает статистику обхода
Повысить эффективность обхода интернет-ресурса также можно с помощью файлов — sitemap и robots. Их робот смотрит в первую очередь. При добавлении на сайт нового раздела необходимо сразу сообщить об этому роботу, добавив страницы в карту сайта (sitemap.xml). Здесь же с помощью тегов priority и changefreq указывается частота обновления контента и приоритет индексирования страниц.
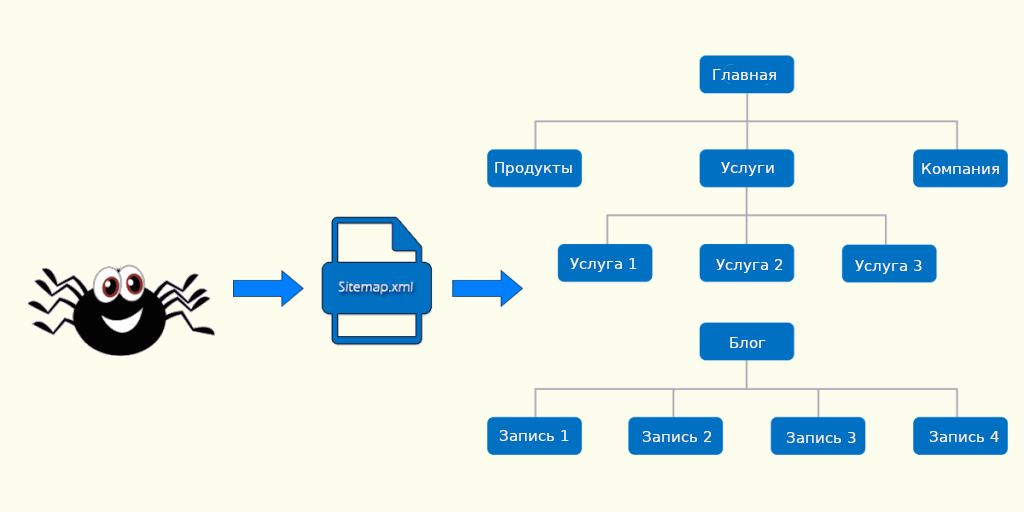
Карта сайта помогает поисковому пауку выстроить маршрут. Источник
В файле robots.txt прописываются рекомендации для роботов и настраивается запрет на индексацию отдельных страниц.
Обычно разработчики сайтов закрывают от глаз краулеров личные кабинеты, формы и корзины пользователей. Чтобы избежать утечек конфиденциальных документов и изображений, важно также помещать их только в недоступных боту разделах сайта под тегом noindex.
Главные мысли







