

Индексация сайта — это добавление и периодическое обновление информации о сайте в каталоге поисковой системы — в индексе.
Поисковики сканируют страницы с помощью роботов-краулеров. Название происходит от английского «crawler» — «обходчик». Краулеры «Яндекса» и Google называются YandexBot и GoogleBot.
Робот просматривает тексты и медиаконтент на сайте. Затем он передает информацию другим алгоритмам поисковика, которые анализируют качество содержимого страницы. Если сайт проходит все проверки, его добавляют в каталог системы.
Краулер постоянно переобходит страницы, чтобы находить и отправлять в каталог актуальную информацию. Каждый переобход — это повторная индексация сайта. Внесенные на сайт изменения могут улучшить или ухудшить ранжирование.
Когда пользователь пишет запрос, поисковая машина сверяется с каталогом и показывает в выдаче релевантные страницы.
Google проиндексировал сайт Unisender и счел, что он хорошо подходит под пользовательский запрос
Индексация помогает поисковой системе работать быстрее. Без нее поисковая система просматривала бы заново все страницы при каждом пользовательском запросе. Это сильно замедлило бы процесс поиска.
Пользователям индексация помогает получать подходящую информацию. Поисковая система ранжирует результаты по релевантности и качеству.
Бизнесу индексирование помогает сделать свой сайт видимым. Без нее ни один пользователь не сможет найти страницу по поисковому запросу. Если сайт не попадет в каталог поисковой системы, на него зайдут только те, кто знает прямую ссылку.
Как работает веб-индексация
Процесс индексации можно разделить на два этапа.
Сканирование
Робот заходит и изучает страницу. Сначала он ищет robots.txt — файлы, где прописано, можно ли сканировать информацию. Владелец может запретить краулеру читать содержимое. Например, чтобы скрыть персональные данные. Затем робот читает МЕТА-теги — элементы HTML-кода в заголовке страницы. Они содержат ее описание, ключевые слова, управляющие команды для браузера и краулеров. После этого робот просматривает содержимое: тексты, изображения и видео.

Заголовок и META-теги из исходного кода сайта Unisender. Эти данные краулер считывает в первую очередь
Оценка и индексация
Краулер собирает информацию о контенте сайта и передает ее алгоритмам поисковика. Они оценивают контент и вносят данные о сайте в каталог — индексируют.
Алгоритм оценивает качество страницы по многим факторам. Некоторые параметры технические — например, дублирование контента — алгоритм не добавит в индекс две одинаковые страницы. Также в каталог не попадут сайты с мошенническим содержимым. Например такие, которые сразу начинают загружать какой-либо файл на устройство пользователя без его согласия.
Факторов очень много, но на три из них стоит обратить особое внимание: количество ключевых слов, уникальность и польза.
Ключевые слова. Это фразы, которые пользователи пишут в поисковую строку. Если контент страницы содержит ключевые слова, алгоритмы корректнее распознают его смысл и поднимут сайт в выдаче. Желательно писать разные словосочетания, чтобы охватить бо́льшую часть запросов и избежать переспама.
Переспам — избыток ключевых слов, мета-тегов, ссылок или других элементов, которые помогают улучшить ранжирование и видимость в результатах поиска.
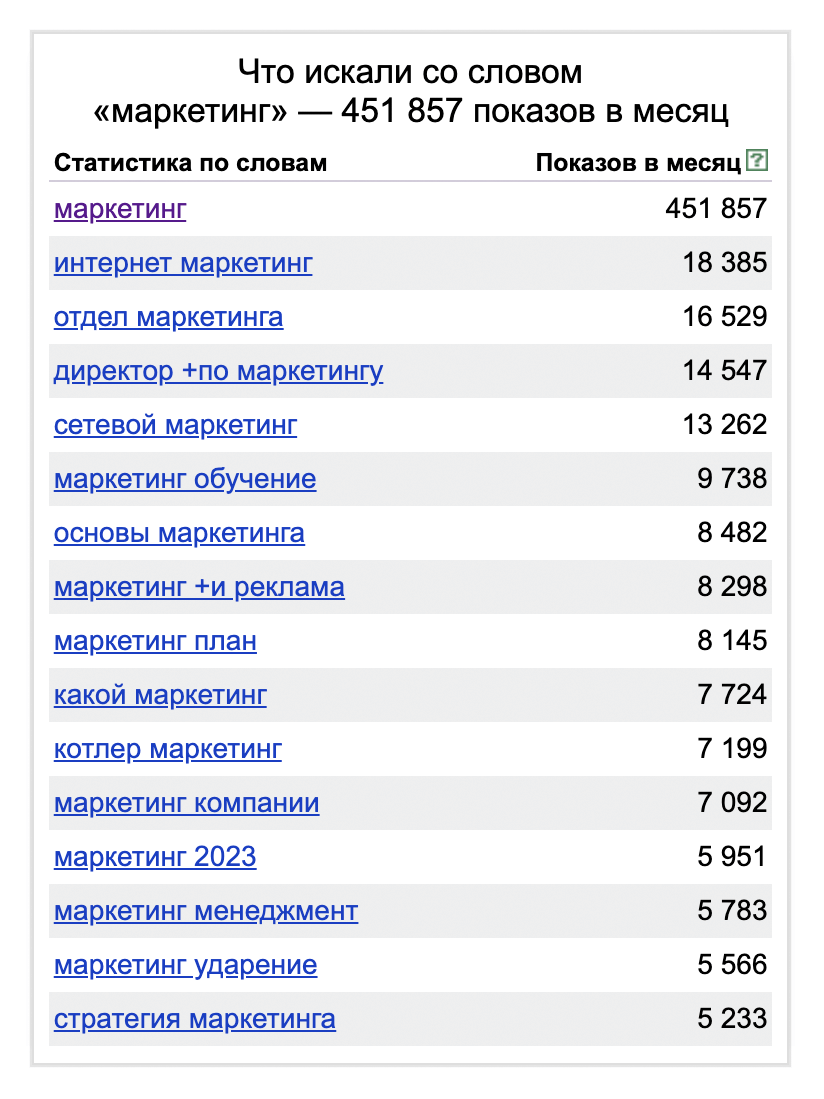
WordStat от «Яндекса» помогает подобрать ключевые слова. Если нужна статья о маркетинге, будет полезно использовать разные словосочетания из этого списка
Важно выдерживать баланс между достаточным количеством ключевых слов и читабельностью текста. Когда робот натыкается на переизбыток ключевиков, он считает, что автор пытается обмануть его. Тогда страницу не добавят в индекс или сильно понизят в поисковой выдаче.
Оптимальная плотность ключевых слов — от 1,5 % до 3 %. Этот параметр можно проверять с помощью веб-сервисов, например, Istio.
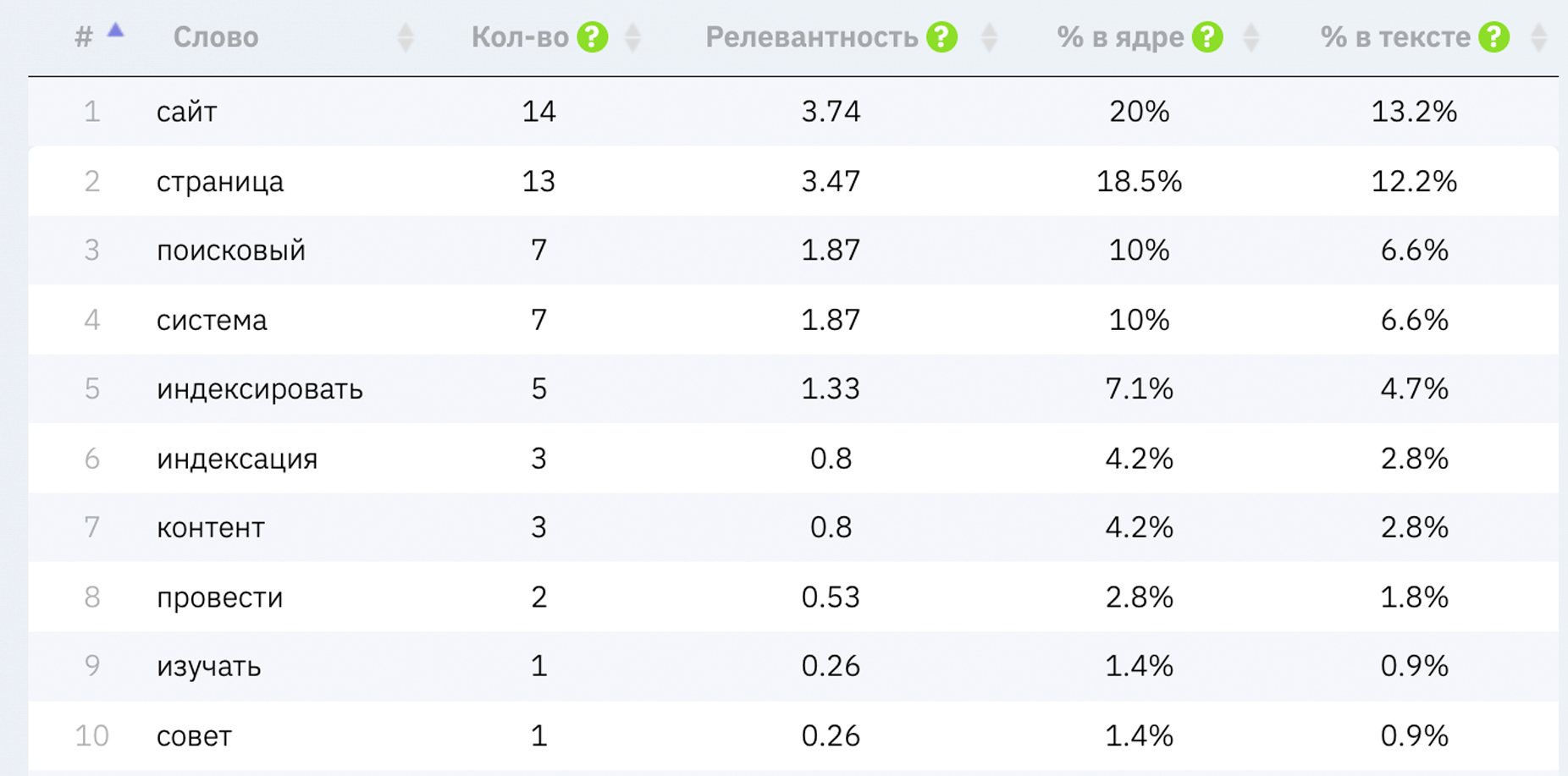
Сильно переспамленный текст. Краулер забанит такую страницу
Уникальность. Алгоритм сочтет контент неуникальным, если он повторяет материал со сторонней страницы. В этом случае поисковик наложит на сайт бан. Страница-плагиатор исчезнет из выдачи или попадет в конец списка.
Иногда в бан попадает текст, который автор писал из головы. Такое случается, когда тема требует цитирования в больших объемах. Например, текст о законе, где нельзя изменять формулировки. В таком случае лучше увеличить общий объем текста, чтобы снизить процент повторов.
Если есть подозрение что текст не уникальный, лучше проверить его на плагиат. Обычно поисковому алгоритму достаточно 80% уникальности.
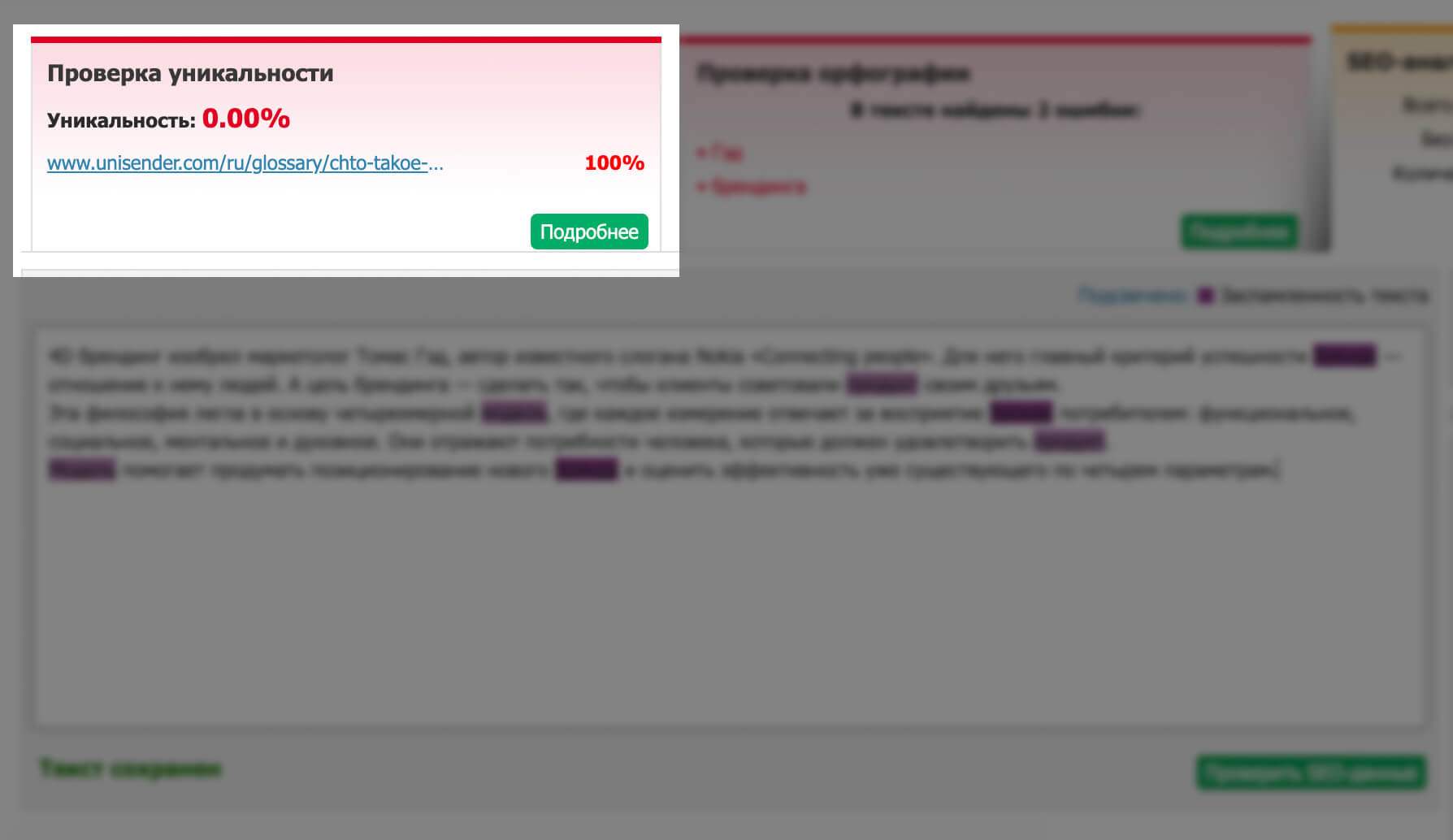
Один из сервисов по поиску плагиата сразу нашел текст, скопированный из «Словаря маркетолога» Unisender
Польза. Алгоритм добавляет страницу в каталог, если на ней размещен контент, который полезен для пользователей:
- содержит актуальную информацию;
- отвечает на конкретные вопросы или решает проблемы;
- организован и структурирован с помощью заголовков, подзаголовков, списков и других элементов;
- предлагает практические советы, рекомендации или инструкции;
- не содержит недостоверной или вводящей в заблуждение информации.
Сервисов для проверки пользы не существует, но у Google есть опросник, который поможет проверить текст.
Важно отметить, что работоспособность сервера тоже влияет на индексацию. Робот смотрит не только файл robots.txt, но и на коды ответов сервера. Если сервер не работает, то краулеры не смогут проиндексировать сайт. Роботы могут смотреть только те страницы, которые работают/разрешены. Если не следить за работоспособностью сервера, будут большие проблемы в сканировании и индексации сайт.

Как быстрее добавить страницу в каталог поисковой системы
Краулеры обходят все сайты по расписанию. Чтобы добавить сайт в индекс быстрее, можно присвоить нужным страницам высокий приоритет. Для этого надо воспользоваться специальными сервисами в поисковиках.
Например, у «Яндекса» в сервисе «Вебмастер» есть панель «Переобход страниц». Администраторы сайтов могут вписать до 30 своих страниц, чтобы краулер обошел их раньше, чем планировал. Обновленные страницы появятся в поиске в течение двух недель.
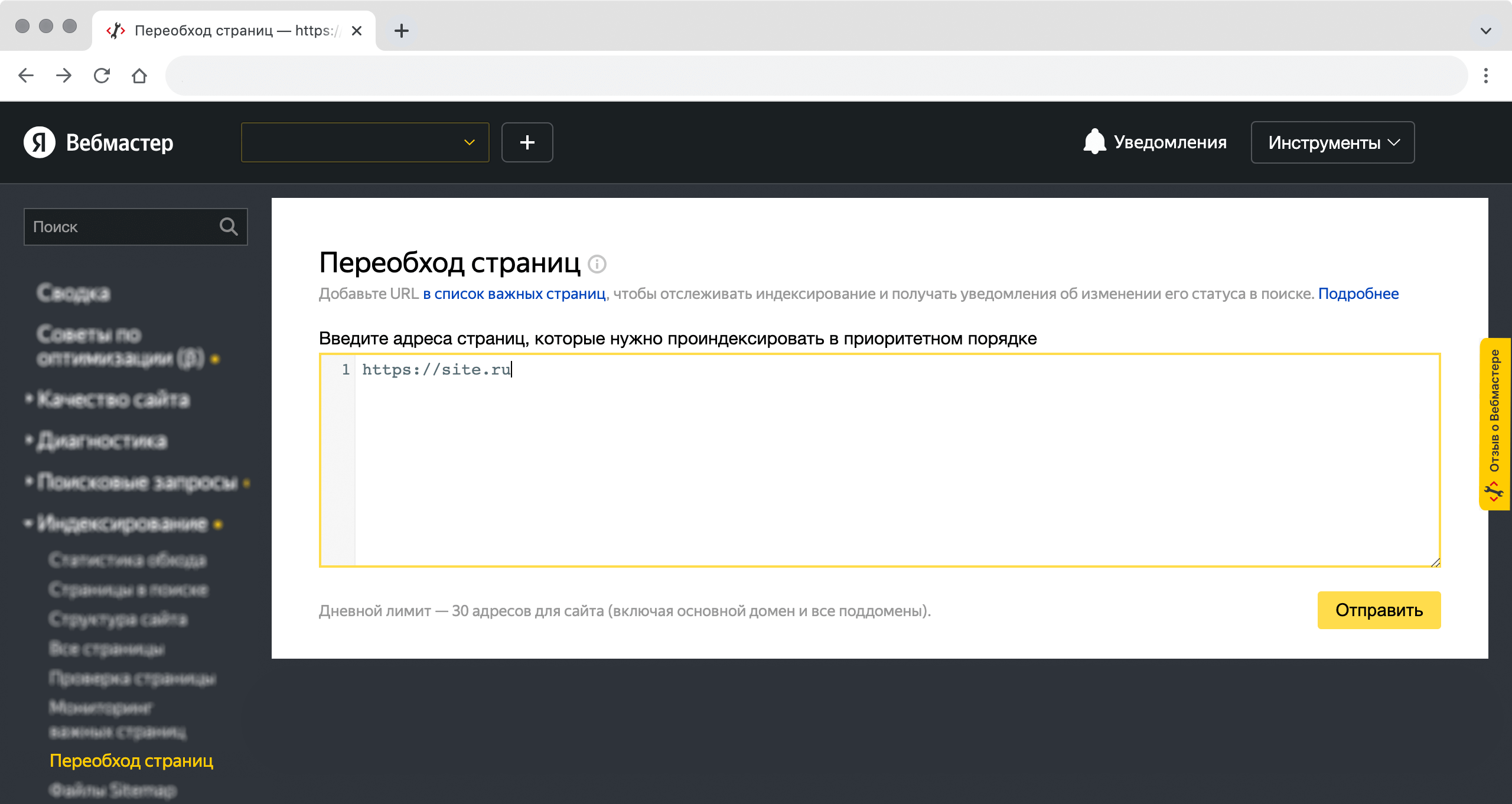
Окно в «Вебмастере», куда надо добавлять страницы для переобхода краулером
Через пару дней можно проверить, добавлена ли страница в базу. Для проверки у всех поисковых систем есть отдельные сервисы.
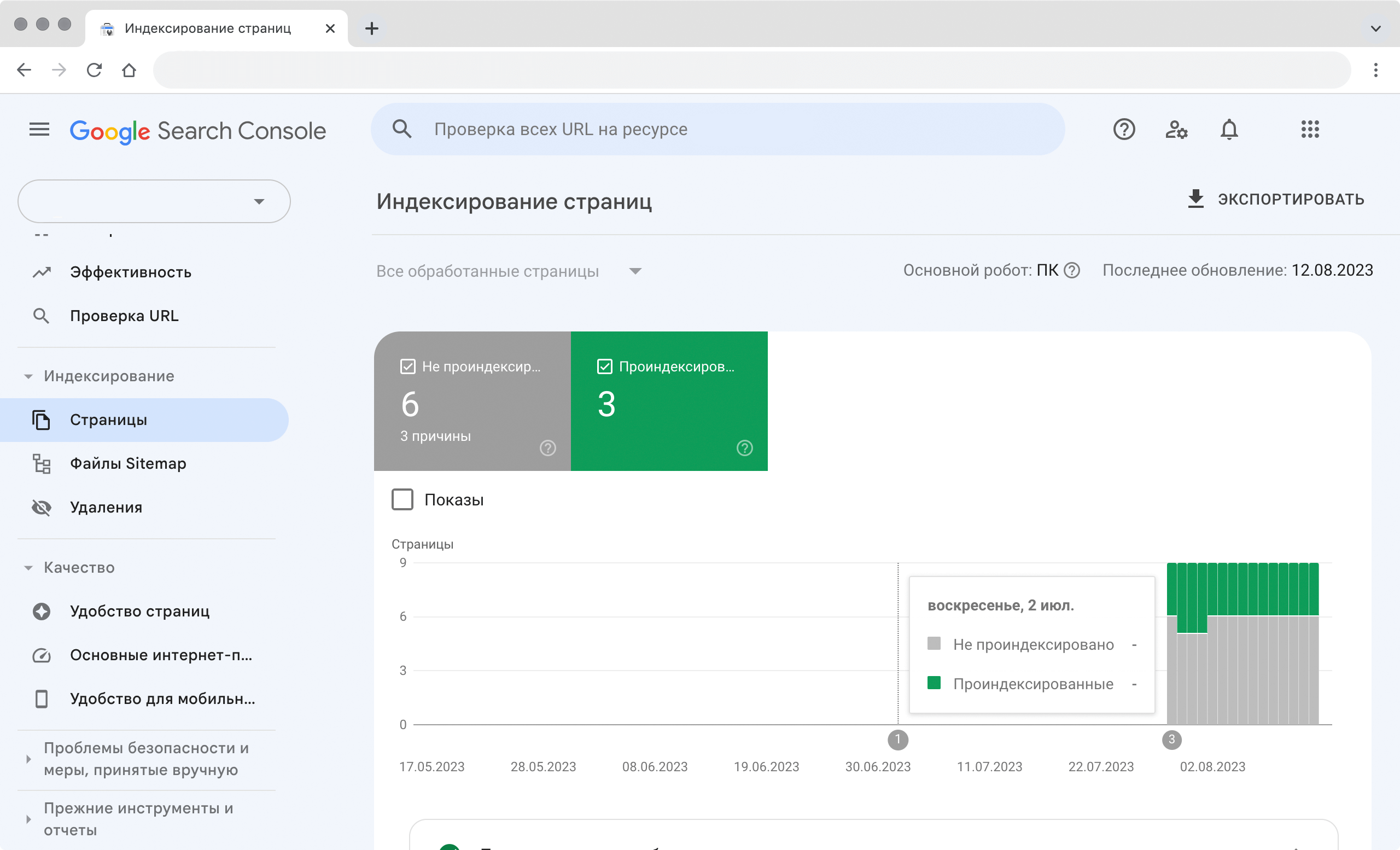
Индексация страниц в Google Search Console. Видны страницы в индексе, дата обхода и ошибки
Как закрыть страницу от индексации
Чтобы краулер не сканировал один сайт слишком долго, его ограничили краулинговым бюджетом — количеством страниц, которое робот сканирует за единицу времени. Когда бюджет исчерпан, краулер уходит на другой сайт. Если он застрянет на страницах, которые не предназначены для пользователей, то не успеет просмотреть основной контент. Чтобы робот не сканировал лишнее, для него прописывают правила.
С помощью специального кода можно закрыть страницу или отдельную ссылку от индексации. Для этого существует несколько способов.
- В исходном коде страницы прописать МЕТА-тег robots с директивой noindex или none. Этот способ подходит для страниц с секретной информацией, которую никто не должен увидеть. Например, с личными данными пользователей.
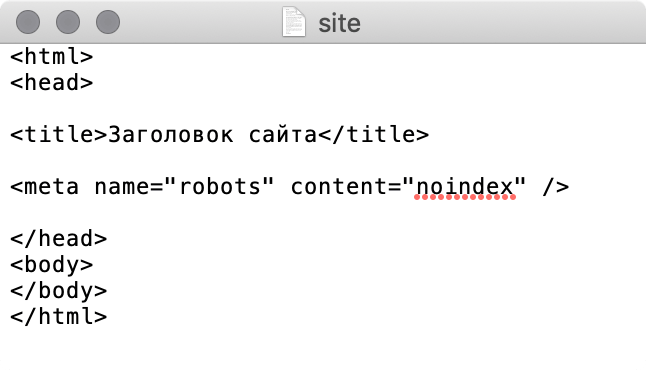
Минимальный код страницы с МЕТА-тегом robots
- Прописать Disallow в robots.txt для страницы или каталога, которые не нужно индексировать. Если ссылка на такую страницу попадет на сторонний сайт, то робот ее все равно проиндексирует. Такой способ подойдет для технических страниц. Например, для тех, которые появляются при ошибке работы сайта.
- Использовать авторизацию на сайте. Если доступ к странице будет доступен только зарегистрированным пользователям, робот не станет ее индексировать.
- В конструкторе сайтов нажать кнопку «Не индексировать» для конкретной страницы.
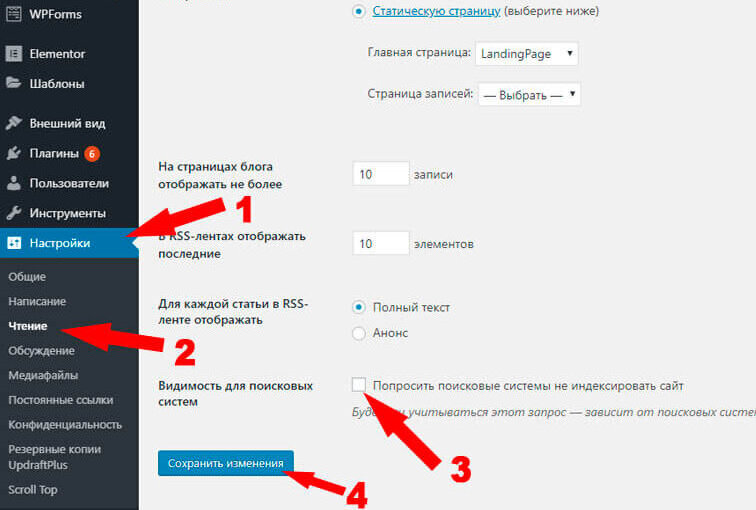
Как запретить индексацию в WordPress. Источник
Главные мысли







