Дедупликация клиентов — это поиск и объединение записей в базе данных, которые относятся к одному и тому же человеку.
Компании собирают информацию о клиентах. Она попадает в базы данных разными способами. Чаще всего ее вносят менеджеры в CRM или же клиенты вводят самостоятельно при регистрации на сайте. Если эта информация поступит в разных форматах, данные могут получиться «грязными»: неполными, содержащими ошибки и дубли.
Дубли — это повторные записи об одном и том же человеке. Информация об одном клиенте попадает в разные учетные записи, по-другому — карточки. Например, пользователь зарегистрировался на сайте, а затем забыл пароль и зарегистрировался заново. Теперь компания считает, что у нее два клиента, но на самом деле это один человек.
Дубли искажают реальные данные об объеме клиентской базы. Ошибка приводит к тому, что компания принимает нерациональные бизнес-решения. Чтобы избежать этого, нужно избавить базу от лишних карточек. Для этого проводят дедупликацию.
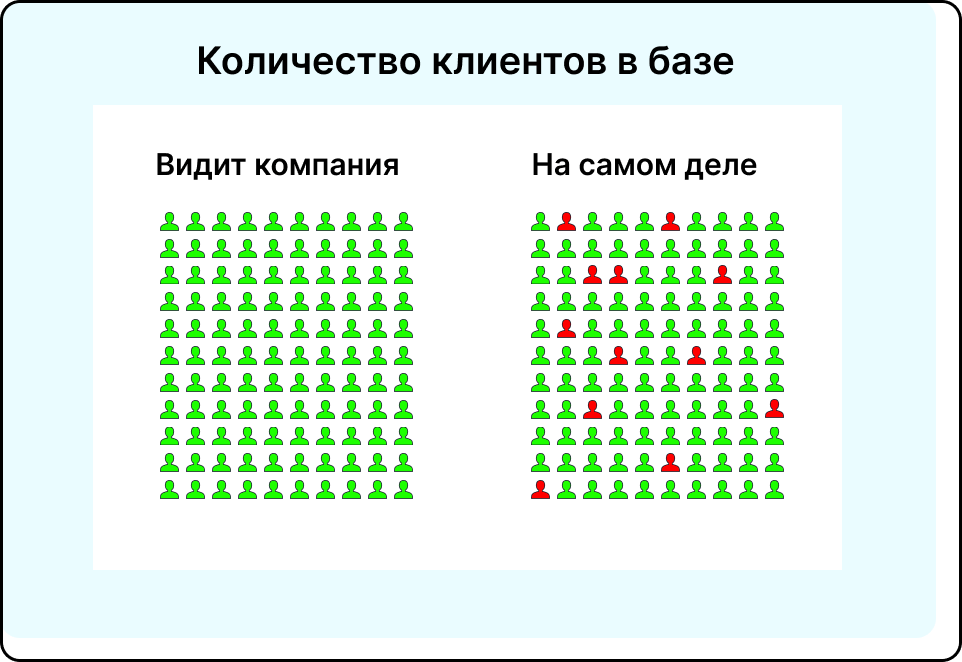
Всего заведено 110 карточек. Из них 12 дублей, то есть 11%. Компания рассчитывает маркетинговые кампании на 110 человек, а на самом деле их только 98. Если клиентская база измеряется в сотнях или тысячах человек, то ошибка на 11% будет иметь серьезные последствия
Как дубли попадают в базу данных
Чаще всего это происходит случайно из-за невнимательности или программных ошибок. Добавить дубликат может любой, кто вносит информацию в базу данных.
Клиенты создают дубликаты из-за технических проблем. Иногда случайно, а иногда и умышленно. К примеру, некоторые люди создают лишние учетные записи, чтобы получать бонусы для новичков. Допустим, скидки за первый заказ.
Стимул создать одноразовый аккаунт
Менеджеры по продажам могут создавать карточки на одного и того же человека несколько раз. Такое случается, если информация о клиенте уже есть базе данных, но внесена с ошибкой. Найти нужную запись невозможно, поэтому менеджер формирует новую.
CRM-система создает дубли при слиянии баз данных. Такое происходит, когда различаются форматы записей. К примеру, в одной базе даты записаны как дд.мм.гггг, а в другой — мм.дд.гггг. Если программа не сверит форматы, появятся дубликаты. Например, клиент родился 5 марта 1987 года. В одной базе данных его день рождения будет 05.03.1987, а в другой — 03.05.1987.
В базу данных попадают полные или частичные дубликаты. Полные — это записи, в которых информация совпадает на 100%. Частичные — это карточки, где пересекаются только некоторые поля. Например, совпадает всё, кроме номера телефона. Это случается по разным причинам: из-за опечаток, неправильной раскладки, внесения данных в неподходящее поле и так далее.
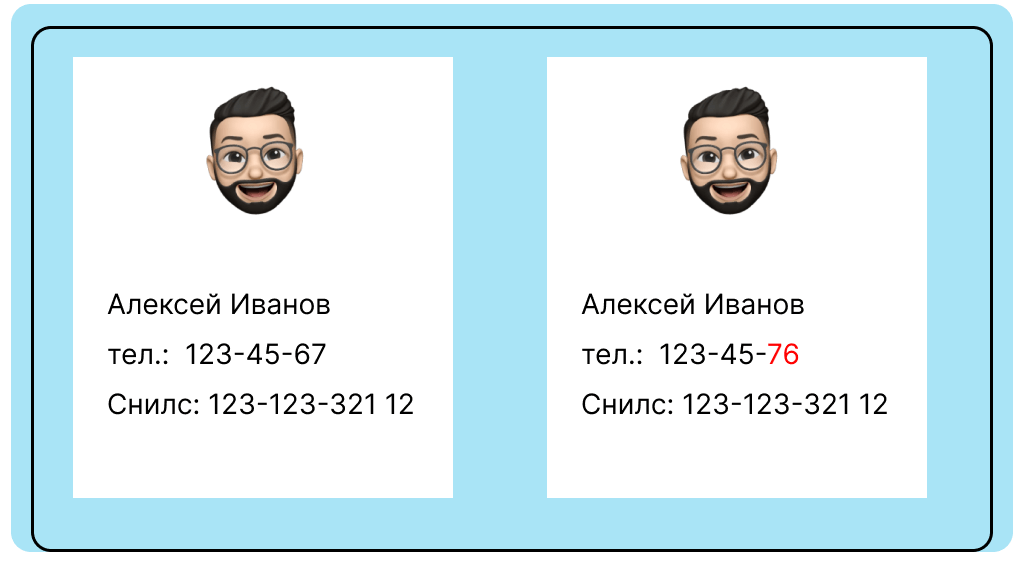
На одной карточке у Алексея номер заканчивается на 67, а на второй — на 76. Снилс и имя совпадают, так что это точно один и тот же клиент. В такой ситуации нужно выяснить правильный номер телефона и объединить данные
В чем опасность дублей в клиентской базе
Повышают затраты на хранение данных. Многие компании рассылают клиентам сообщения: об акциях, новых продуктах и так далее. Каждое отправленное письмо занимает место на сервере.
Аренда или покупка хранилища для цифровых данных стоит денег. Соответственно, если присылать клиенту одно сообщение по два-три раза, то и места понадобится в два-три раза больше.
Увеличивают затраты на рекламу. Бюджет маркетинговых кампаний и стоимость отдельных инструментов для продвижения зависят от объема клиентской базы.
Например, многие организации пользуются сторонними сервисами для email-рассылок. Цена на подписку обычно зависит от количества адресатов: чем их больше, тем выше стоимость. Дубли делают сервис дороже, но не приносят прибыли.
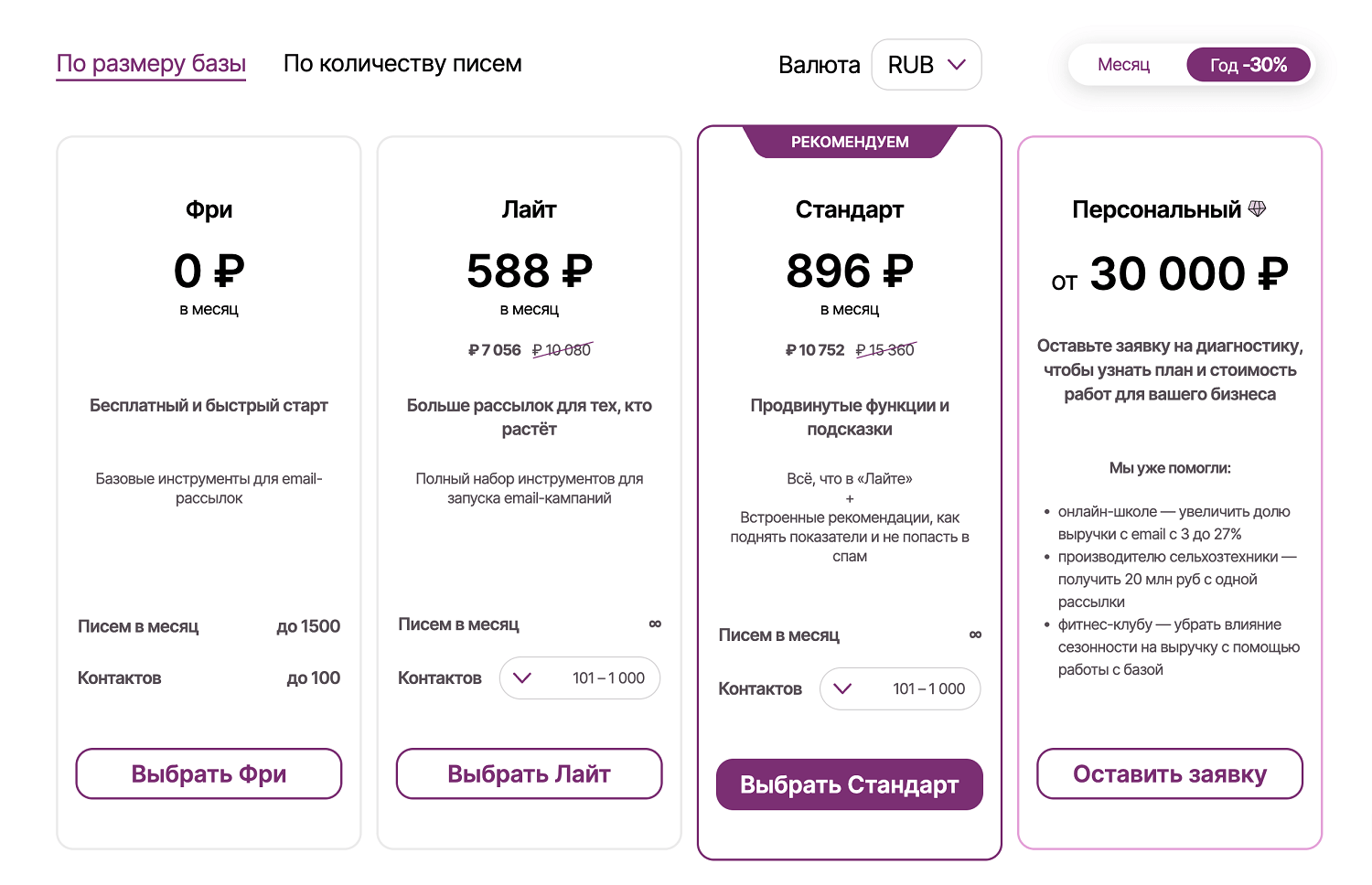
Стоимость рассылок Unisender в зависимости от размера базы. Если у компании 1010 адресов, 20 из которых — дубли, то она уже не сможет воспользоваться стандартным тарифом и будет вынуждена выбрать более дорогой
Понижают репутацию компании. Если один и тот же email попадает в разные записи о клиентах, то человек получает письма от бренда по несколько раз. Такая ситуация злит, особенно, если клиент не сам зарегистрировался с разных почтовых адресов. В лучшем случае он отпишется от рассылки, а в худшем — сообщения получат пометку «СПАМ».
Ухудшают качество бизнес-решений. Дубли искажают данные, на основе которых принимают решения. Например, компания анализирует повторные продажи. Исследование показывает, что многие клиенты делают один заказ, а затем уходят. Организация принимает решение стимулировать повторные продажи,чтобы исправить ситуацию.
Но на самом деле проблема в дубликатах. Заказы делают одни и те же люди, но с разных аккаунтов. Программа считает такие покупки первичными и формирует соответствующий отчет, а бренд тратится на лишнюю рекламную кампанию.
Как проводят дедупликацию данных
В программе для работы с таблицами
Все программы наподобие Excel имеют встроенные фильтры, которые можно использовать для поиска и удаления или объединения дубликатов. Этот метод эффективен только для небольшой базы.
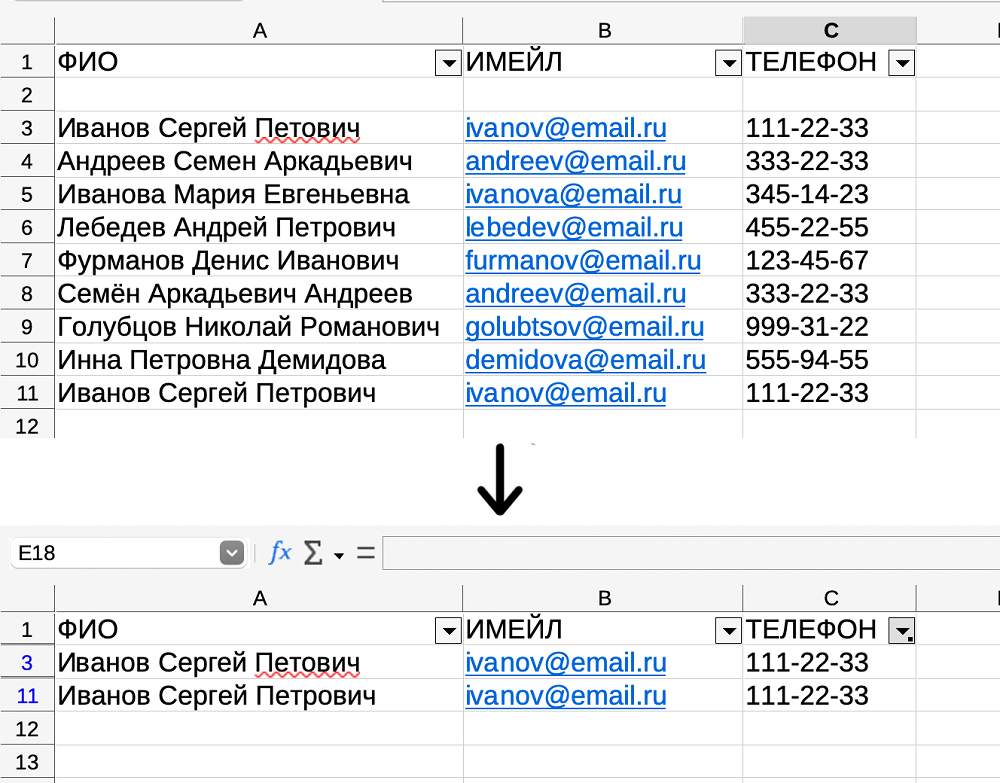
В базе есть минимум две строки, которые дублируют информацию об одном клиенте — Иванове Сергее Петровиче. Выявить это можно, если применить фильтр к столбцу с телефоном или email
С помощью SQL-запросов
SQL — это язык программирования, на котором создают базы данных. SQL-запросы — это команды, с помощью которых управляют такими базами.
Чтобы провести дедупликацию, потребуется пройти три этапа:
- Предварительно привести все данные к общему виду. Сделать одинаковый регистр, превратить букву «Ё» в «Е», убрать лишние пробелы, унифицировать формат ввода информации. После обработки сформируются группы из потенциальных дублей.
- Проверить основания, по которым образовались самые крупные группы из вероятных дубликатов. Это нужно, чтобы случайно не объединить карточки клиентов по пустым или «мусорным» полям. Например, могут появиться пять групп по три карточки и одна с 15 карточками. Скорее всего, эти 15 «дублей» объединились по неправильному признаку. Например, потому что все они имеют пустое поле.
- Провести дедупликацию с разными сочетаниями значений полей. Например, проверить поля «ФИО», «email» и «номер телефона» в комбинациях «ФИО»+«email», «email»+«номер телефона» и «ФИО»+«номер телефона». Затем результаты объединить и найти пересечения. Это называется таблицы дедупликации, с их помощью находят сложные дубликаты.

Такой метод называют таблицей дедупликации. Так выглядит ее скрипт. Источник
С помощью сторонних сервисов
Если нет возможности применить SQL-запросы, можно использовать специальные программы для дедупликации. На рынке существуют платные и бесплатные инструменты. Например, Datablist, OpenRefine или Loginom Data Quality.
OpenRefine с загруженной базой для дедупликации. Программа может очищать данные и проводить дедупликацию. Источник
Платные сервисы требуют денег, зато имеют существенные преимущества:
- Используют более сложные алгоритмы для определения дубликатов, что уменьшает количество ошибок.
- Предлагают больше функций: настройку параметров поиска, фильтрацию результатов и экспорт данных.
- Предоставляют своевременную техническую поддержку клиентам.
- Используют шифрование данных и другие методы защиты, поэтому гарантируют безопасность.
Главные мысли







