

Big Data (большие данные) — это разнообразные данные больших объемов, которые хранятся на цифровых носителях. В их число входит общая статистика рынков и личные данные пользователей: информация о транзакциях и платежах, покупках, перемещениях и предпочтениях аудитории.
Объем больших данных исчисляется терабайтами. Это и тексты, и фотографии, и машинный код. Такой массив информации просто невозможно проанализировать силами человека или с помощью обычного компьютера, для этого нужны специальные инструменты.
Технологии, связанные с хранением и обработкой больших данных, также называют Big Data.
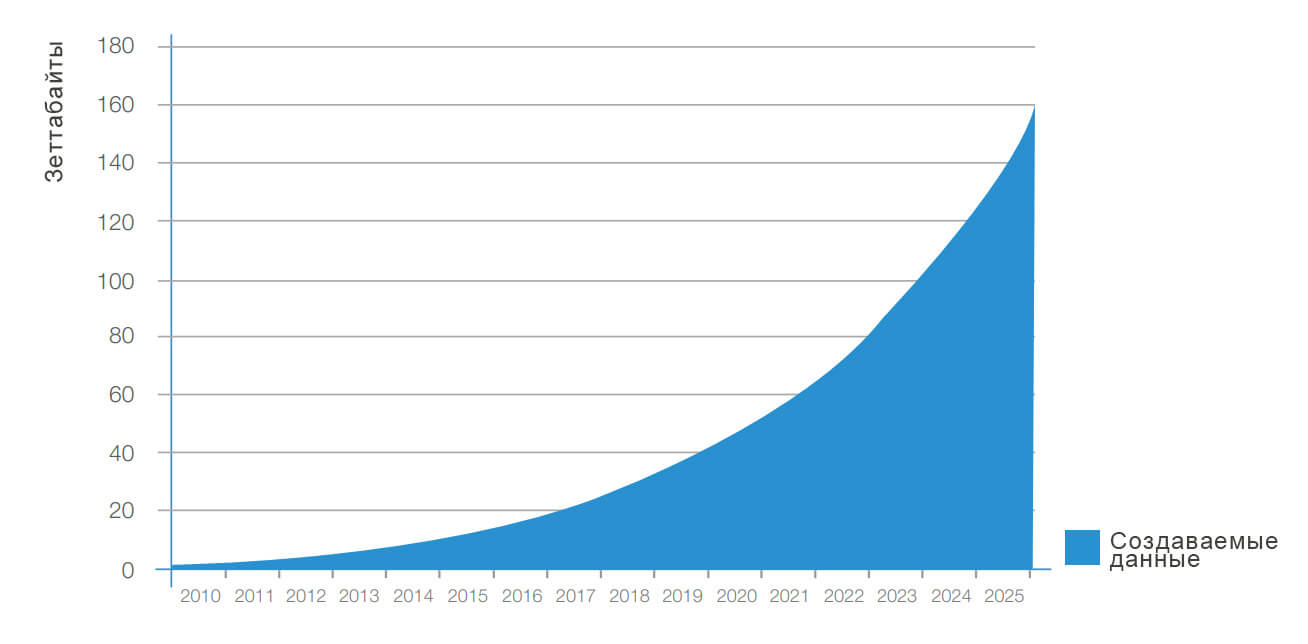
Прогноз роста больших данных в мире
Характеристики Big Data
Большие данные отличают от обычных наличие признаков «VVV».
Volume (объем) — физический размер данных, их вес и количество места, которое они занимают. Поток таких данных может составлять от 100 Гб в сутки.
Velocity (скорость) — объем информации увеличивается с большой скоростью, в геометрической прогрессии, и требует быстрой обработки и анализа.
Variety (разнообразие) — данные неоднородны и поступают в разных форматах: текст, картинки, голосовые сообщения, транзакции. Они могут быть неупорядоченными, структурированными полностью или частично.
Отдельные IT-компании выделяют дополнительные аспекты работы с большими данными.
Variability (изменчивость) — поток информации неоднороден, случаются всплески или спады. Это осложняет её обработку и анализ.
Value (ценность) — описывает как сложность информации для обработки, так и её степень важности. Для бизнеса особо актуален вопрос целесообразности затрат на обработку данных.
Visualization (визуализация) — возможность наглядно представить результаты анализа, чтобы упростить их восприятие человеком.
Veracity (достоверность) — точность и достоверность самих данных, а также корректность способа, которым получены. Неточности ведут к ошибкам в анализе.
Зачем нужны большие данные
Большие данные применяются во многих отраслях: банки, страхование, ритейл, здравоохранение, логистика, наука, маркетинг. Везде, где можно собрать большой объем информации и проанализировать его.
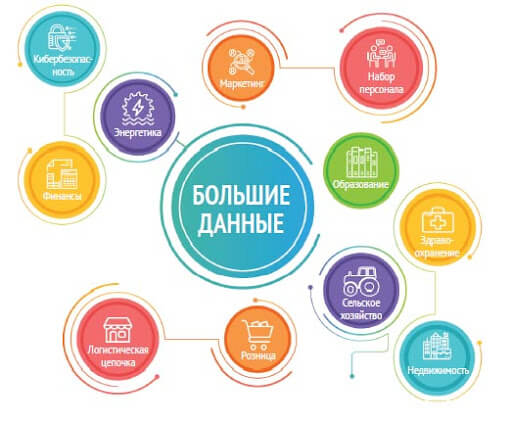
Отрасли, которые используют BigData. Источник
Перед BigData стоит три глобальных задачи:
Строить модели. Систематизировать данные, находить причинно-следственные связи. Это помогает понять, как работают сложные системы, делает их прозрачными.
Производители автомобилей Toyota изучили поведение водителей в момент аварии и разработали систему безопасности. Она анализирует манеру вождения и срабатывает, если человек за рулем перепутал педали.
Поисковый отряд «Лиза Алерт» совместно с «Билайн.Поиск» запустили нейросеть, чтобы обрабатывать фотографии со спутников. А еще они используют алгоритм, который вычисляет потенциальных свидетелей и высылает им информацию о пропавшем человеке.

Оптимизировать процессы. Автоматизировать рутинные или трудозатратные этапы, повысить точность расчетов и экономить ресурсы. Например, сервисы такси автоматически рассчитывают стоимость поездки с учетом спроса, пробок и погоды.
«Магнитогорский металлургический комбинат» внедрил систему, которая в режиме реального времени анализирует параметры плав и выдает рекомендации оператору цеха, что позволяет минимизировать издержки.
Amazon оптимизирует продажи и обновляет цены на сайте примерно каждый 10 минут. Также предлагает дополнительные скидки, после добавления товара в корзину, чтобы уменьшить число брошенных товаров.
Розничная сеть Target показывает разную стоимость товаров для жителей престижных и обычных районов, чтобы максимизировать выручку.
Делать прогнозы. Бизнес с помощью аналитики предсказывает поведение покупателей и спрос, планирует продажи и денежные потоки. Искусственный интеллект эффективнее врачей может выявлять болезни на ранней стадии.
Магазины предлагают персональные рекомендации и скидки для покупателей, которые с большей вероятностью им понравятся.
Застройщики с помощью систем динамического ценообразования определяют максимально выгодную стоимость объектов недвижимости на данный момент, прогнозируют прибыль и выполнение плана продаж.
Как работает технология больших данных
Работа с большими данными происходит в несколько этапов:
- сбор информации из разных источников;
- размещение данных в хранилище;
- обработка и анализ.
Сбор информации
Информация окружает нас повсюду. Социальные сети, поисковые системы, гаджеты, карты лояльности, данные GPS-трекеров, онлайн-кассы генерируют большие потоки данных каждую минуту. Источники Big Data можно разделить на три типа: социальные, машинные и транзакционные.
Социальные — создаются людьми. Информация, которую загружают или создают пользователи интернета: фотографии, электронные письма, сообщения, статьи, записи в блогах. Сюда же относят социально-демографическую статистику стран и компаний.
Транзакционные — возникают при совершении различных операций. Это покупки, переводы денег, поставки товаров, операции с банкоматами, переходы по ссылкам, поисковые запросы.
Машинные — информация с датчиков и устройств. В том числе интернет вещей — данные, которыми устройства обмениваются между собой. Например, датчики внутри автомобилей, метеорологические приборы, смартфоны, умные колонки и т.д.
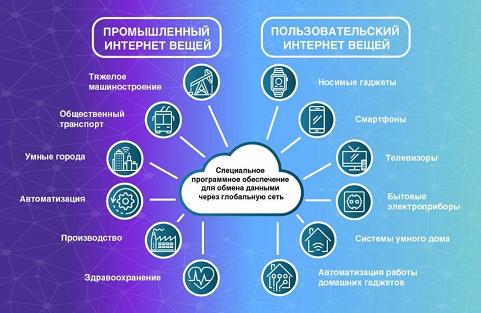
Что входит в интернет вещей. Источник
Хранение
Большие объемы информации требуют больших мощностей для размещения. У компании, которая собирает Big Data, есть три варианта, где хранить данные:
- На собственных серверах. Предприятие самостоятельно закупает, настраивает и обслуживает оборудование.
- Облачное хранение. Фирма арендует место у сторонней компании за плату. Такую услугу предоставляют Amazon, Microsoft или Google. Ряд платформ, помимо хранения, предлагают готовые решения для обработки данных, например Oracle Exadata.
- Публичные большие данные. Хранятся облачно либо на частных серверах, доступ к базе предоставляется бесплатно.
У различных видов хранения есть свои плюсы и минусы:
1. На своём сервере. Это может быть дешевле, но вопросы безотказности, безопасности и поддержки вы должны будете решать сами.
2. В облаке. Это может быть дороже, но вопросы безотказности, безопасности и поддержки будут решаться на стороне облака.

Анализ
Существует 4 вида аналитики, которые отличаются по задачам, уровню сложности и участию людей.
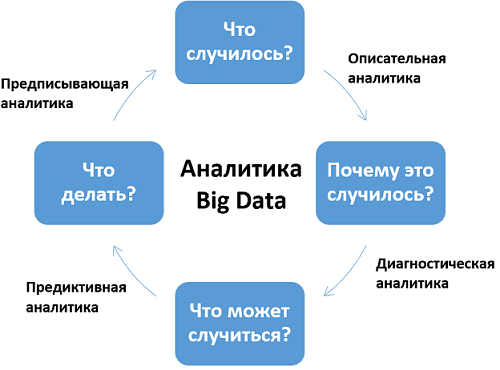
Описательная — самая простая форма аналитики, которая описывает текущую ситуацию с помощью простых арифметических операций. Используется в счетчиках событий (лайков, репостов), веб-аналитике, социологических опросах, анализе продаж. Результаты описательной аналитики понятны широкому кругу лиц.
Диагностическая — выявляет закономерности и отклонения от нормы, ищет причины событий. Использует статистические методы. Помогает понять, что привело к поломке автомобиля или падению продаж.
Предиктивная — исследует тенденции и закономерности, чтобы прогнозировать события в будущем. Использует алгоритмы, основанные на вероятностях, и машинное обучение. Помогает предсказывать поведение покупателей, объем выручки, определять кредитный рейтинг заемщика.
Предписательная — анализирует разные сценарии развития событий, предлагает наиболее эффективные действия в текущей ситуации. Использует более сложные математические алгоритмы, машинное обучение и Data Maning. Помогает оптимизировать производство и бизнес-процессы, предотвратить аварии или убытки.
Методы и техники анализа и обработки
Рассмотрим основные методы и техники работы с большими данными.
Краудсорсинг — ручной анализ, к которому привлекают большое количество интернет-пользователей. Например, фильтрация цен или поиск контента с определенными параметрами.
Визуализация — построение графиков и визуальных моделей. Они упрощают понимание результатов анализа.
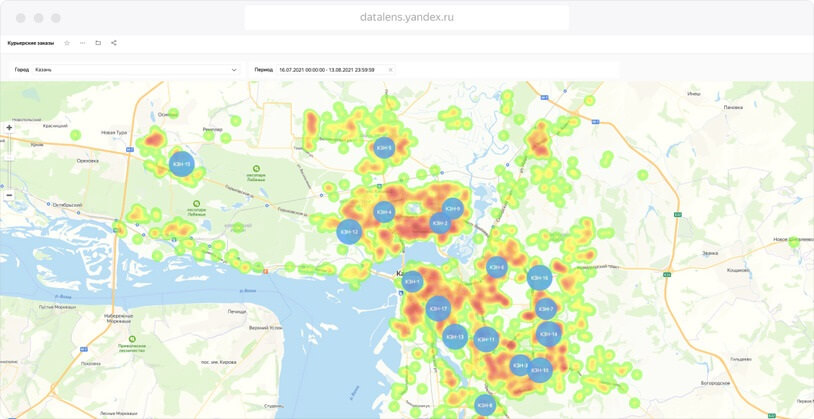
Компания Kazan Express использовала визуализацию геоданных для открытия новых пунктов выдачи. Источник
Машинное обучение — искусственный интеллект ищет закономерности и делает прогнозы с помощью математических методов, в том числе распознает образы. Прогнозирование помогает предсказывать поведение людей и принимать эффективные решения.
Имитационное моделирование — на основании данных строится модель системы, которая существует в реальности. Над ней проводят эксперименты, чтобы имитировать события и понимать, как они влияют на систему.
Смешение и интеграция данных — способ объединить данные из разных источников, чтобы дополнять и увеличивать общую базу.
Data Mining — глубинный анализ, структурирует и выявляет закономерности. Использует математические алгоритмы и статистические методы, например дерево принятия решений или нейронные сети. Data Mining — это совокупность различных методов.
Big Data в маркетинге
Для маркетологов наибольшее значение имеют четыре типа данных:
- о клиентах — социально-демографические, поведенческие, предпочтения, интересы;
- о конкурентах — цены, клиенты, реклама, продажи;
- об операциях — метрики маркетинговых кампаний;
- о финансах — продажи, прибыль, издержки.
Практические задачи бизнеса и маркетинга, которые помогают решать большие данные:
Сегментировать рынок. Точнее разбить потребителей на группы по интересам, предпочтениям, способам покупки.
Создать портрет целевой аудитории. Собрать и систематизировать подробные данные о текущих клиентах.
Персонализировать рекламу. Интернет-маркетинг использует большие данные, чтобы оптимизировать таргетированную и контекстную рекламу. Повысить кликабельность, снизить цену за клик, настроить ремаркетинг.
Прогнозировать поведение потребителей. Предсказывать реакции на рекламную кампанию, спрос и модели потребления.
Создавать и совершенствовать продукты. Анализировать причины популярности востребованных товаров, выявлять недостатки продукта и потребности клиентов.
Оптимизировать издержки. Снижать расходы на рекламу и продвижение, на логистику, управлять товарными запасами и трудовыми ресурсами.
Персонализировать предложения. Увеличить количество повторных и кросс-продаж. Рекомендовать пользователю актуальные и интересные продукты, предоставлять акции и скидки индивидуально.
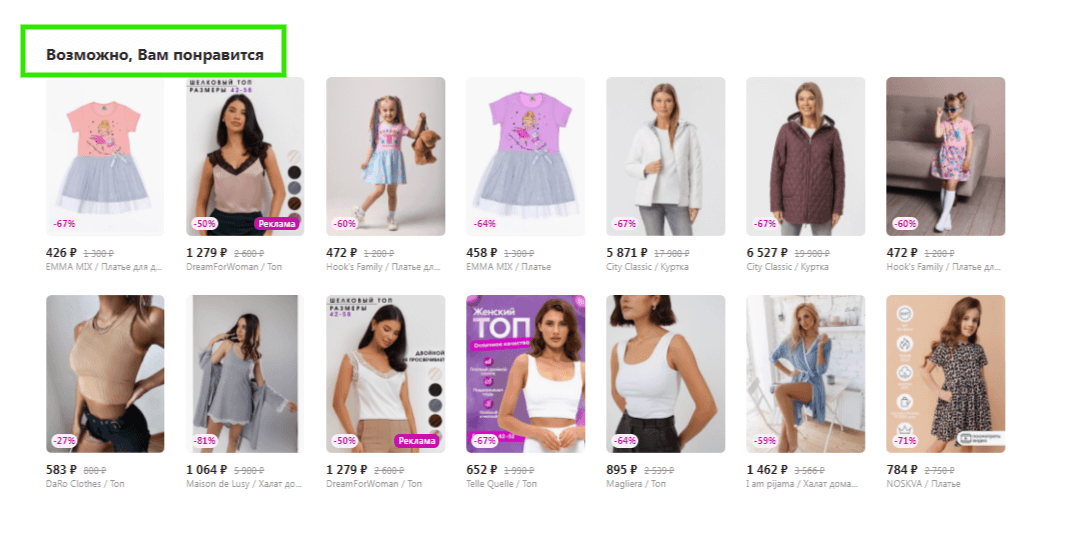
Подобный блок есть в каждом маркетплейсе. Алгоритмы предлагают пользователю продукты на основе его предпочтений и ранее просмотренных товаров
Big Data и персональные данные
Значительную часть Big Data составляют персональные данные. Это информация, которую прямо или косвенно можно отнести к конкретному пользователю. Для сбора и обработки персональных данных компания должна получить согласие пользователя. Например, попросить поставить галочку в соответствующем поле при подписке или разместить предупреждение на сайте.

Форма на сайте Elizavecca
Для аналитики большие данные шифруют и обезличивают, но этого недостаточно для обеспечения безопасности. В российском секторе интернета происходит от 10 случаев кражи баз в год. При этом большая часть происходит по вине сотрудников компании.
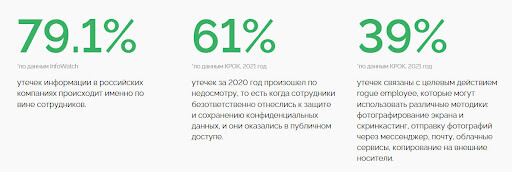
Пользователи не могут контролировать утечку и зачастую в полной мере не представляют объем и разновидность данных, которые они передают компаниям.
Главные мысли







